


New AI tools let you play inside your prompts.
Just when you thought AI video was getting good, Google DeepMind previewed Genie 3, a new “world model” that generates an entire interactive world from a single text prompt.
Forget passively watching. With Genie 3, you can navigate these AI-generated environments in real-time at 24 frames per second. It’s like playing a video game where the level is created on the fly from your imagination.
The variety is stunning. Users can explore fantastical realms, historical settings, and photorealistic landscapes.
Here are a few examples of worlds generated from a simple prompt:
- A high-speed drone flight through a narrow canyon in Iceland.
- Walking around ancient Athens, complete with detailed marble architecture.
- A jellyfish swimming through the deep sea between volcanic vents.
- A whimsical, animated creature bounding across a rainbow bridge.
So pretty pumped, right? Well, all you have to do is… oh wait, you can’t! For now, Genie 3 is only available in a limited preview for select academics and creators.
Now here’s the real story...
Google isn't alone. An entire category of world-building (and even game building) AI has suddenly exploded onto the scene, and many of them are open-source.
Just in the past few weeks, we’ve seen:
- Matrix-Game 2.0: An open-source model from SkyworkAI that generates interactive, minute-long game worlds at 25fps. It’s trained on 1,200 hours of gameplay from GTA5 and Unreal Engine.
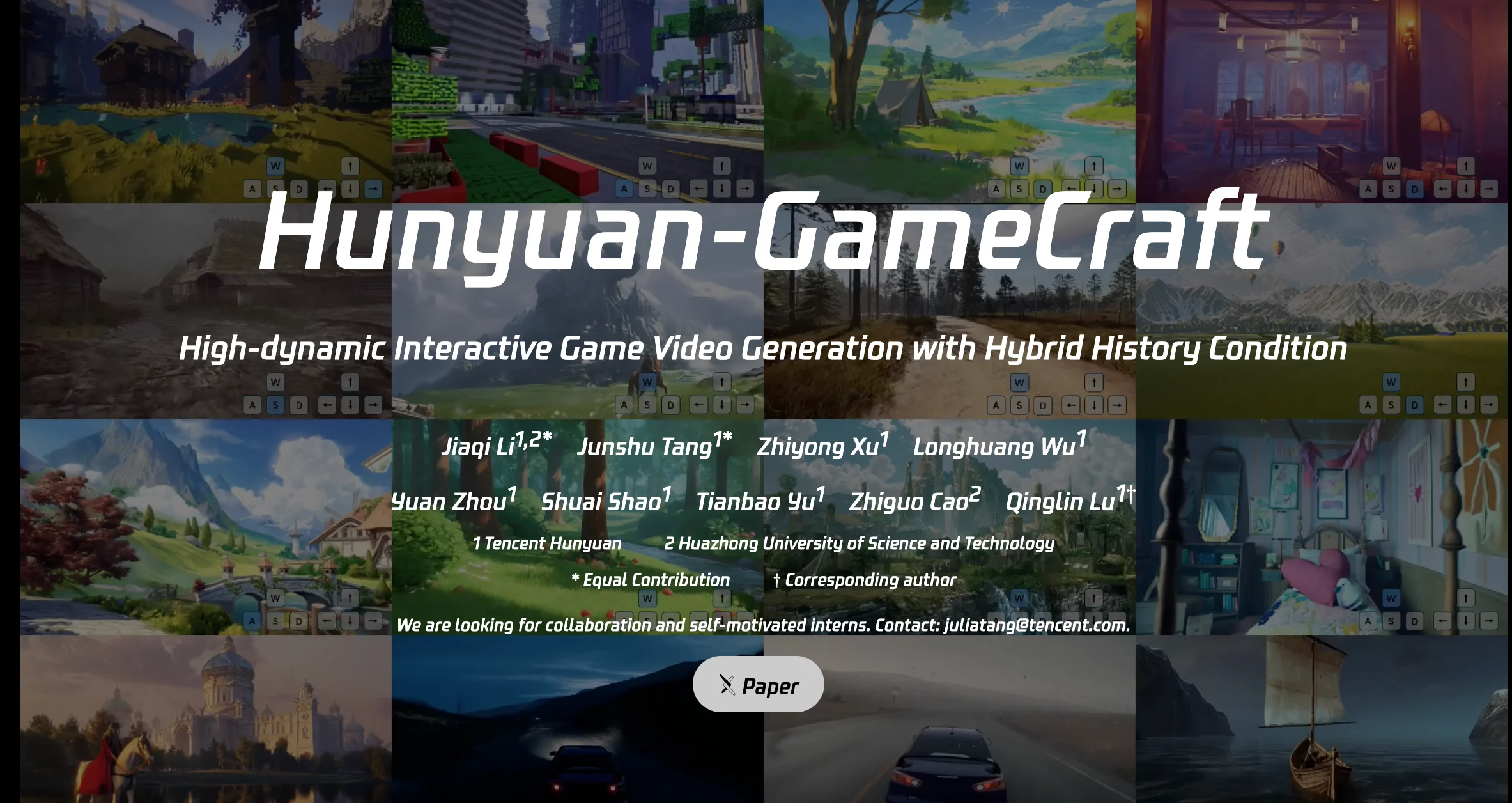
- Hunyuan Gamecraft: Tencent’s model, trained on over 100 AAA games, focuses on creating high-dynamic, controllable game videos.
- Matrix-3D: Another open-source tool from SkyworkAI, this one builds explorable, 360-degree panoramic worlds from a single image or text prompt.
So what makes these new "world models", or really, "Game models" unique?
One of Genie 3’s most groundbreaking features is what Google calls "promptable world events." This allows a user to intervene mid-simulation with text commands, altering the environment on the fly. You could be exploring a serene beach and then type "a hurricane approaches" to see the weather change dynamically. This leap from passive viewing to active participation marks a fundamental shift in generative AI.

According to Google, this consistency isn't achieved through traditional 3D modeling techniques like NeRFs or Gaussian Splatting, which require an explicit 3D representation. Instead, Genie 3’s consistency is an emergent property. It generates the world frame by frame, using its deep understanding of physics and context to decide what should come next based on the user's actions and the history of the simulation.
The Open-Source and Corporate Contenders
The first open-source model from Skywork, Matrix-Game 2.0, is a direct competitor to Genie 3's interactive function. It's an open-source world model that can generate long, interactive videos "on-the-fly" at a smooth 25fps. Unlike Genie, which is trained on a wide variety of data, Matrix-Game 2.0 is unapologetically focused on gaming. It was trained on a massive 1,200-hour dataset of gameplay footage from popular engines like Unreal Engine and Grand Theft Auto V. Its key feature is a "mouse/keyboard-to-frame" module that allows for precise, frame-level control, making it feel less like a simulation and more like an actual game.
Here's the code, the HuggingFace page, and the technical paper breaking it down.

Their other offering, Matrix-3D, tackles a different part of the world-building problem. Instead of real-time interaction, it focuses on generating vast, omnidirectional, and fully explorable 3D worlds from a single text or image prompt. It works by combining panoramic video generation with 3D reconstruction, creating a 360-degree scene that a user can freely explore. While it requires hefty hardware, the promise of creating a complete 3D environment with one command is a tantalizing prospect for designers and artists.
Meanwhile, Chinese tech giant Tencent has thrown its hat in the ring with Hunyuan Gamecraft (paper). This framework is engineered specifically for high-dynamic, interactive game video generation. Trained on a staggering dataset of over one million gameplay recordings from more than 100 AAA games, Hunyuan Gamecraft aims to replicate the look and feel of polished, commercial games. It cleverly unifies keyboard and mouse inputs into a single camera representation, allowing for incredibly smooth and fine-grained control over movement. It also uses a "hybrid history-conditioned" training method to ensure that as players move through the world, the environment remains consistent, even when they turn back to where they started.
Adding to the mix is the ambitious Yan framework, which breaks down interactive video generation into three parts: Yan-Sim for high-fidelity simulation (targeting 1080p at 60fps), Yan-Gen for creating content from multimodal prompts, and Yan-Edit for altering the generated world with text commands.
Think of Yan not as a single AI model, but as a complete production studio for creating interactive worlds. It's a framework that breaks the complex task into three specialized modules:
- Yan-Sim (The Simulator): This is the core engine. Its goal is to create a high-quality, interactive simulation. It’s incredibly ambitious, targeting 1080p resolution at 60 frames per second (fps)—a significant jump in quality and smoothness compared to competitors like Genie 3 (720p at 24fps). It works by generating each frame based on the previous ones and the player's actions.
- Yan-Gen (The Generator/Artist): This module’s job is to create the actual video content. It takes all kinds of inputs—text prompts, reference images, and action commands—and uses them to generate diverse and highly controllable interactive scenes, from realistic games to open-world scenarios.
- Yan-Edit (The Editor): This is arguably the most unique part. It allows you to edit the generated world in real-time using text commands. This goes beyond just simple changes. You can perform:
- Structural Editing: Add new interactive objects into the scene.
- Style Editing: Change the color, texture, or look of existing objects.
In essence, the Yan framework is building a comprehensive toolkit that lets you simulate a world (Sim), generate its visual content (Gen), and then modify it on the fly (Edit), aiming for a level of quality and performance that would rival a real video game engine.
The Engine Under the hood: Self-forcing
This sudden, simultaneous leap forward isn't a coincidence. It's largely thanks to a foundational breakthrough in AI training called Self-Forcing.
For years, video generation models have struggled with a "training wheels" problem. During training, they would learn to create the next frame of a video by looking at a perfect real frame. But when asked to generate a video on their own, they had to rely on their own, slightly imperfect previously generated frames. The errors would quickly add up, and the video would degrade into a chaotic mess.
Self-Forcing solves this. It's a new training method that, in simple terms, makes the AI practice how it will perform in the real world. Here's how it works:
The Old, Flawed Way (The "Training Wheels" Problem):
Imagine you're teaching an AI to generate a video, frame by frame. Traditionally, to generate Frame 2, you'd show it the perfect, real Frame 1 from your training data. To generate Frame 3, you show it the perfect, real Frame 2, and so on. The AI always has perfect "training wheels."
The problem? When you later ask the AI to generate a brand new video on its own, it has to create Frame 2 based on the Frame 1 it just made, which might have tiny imperfections. Then it makes Frame 3 based on its (slightly more imperfect) Frame 2. The errors add up, and the video quickly falls apart into a blurry, inconsistent mess. The AI never learned to recover from its own small mistakes. This is called the "train-test gap" or "exposure bias."
The New, Smarter Way (Self-Forcing):
Self-Forcing gets rid of the training wheels. During training, it forces the AI to practice the way it will perform in the real world. To generate Frame 2, it uses the (potentially imperfect) Frame 1 that it just generated.
This teaches the model to be robust and self-correcting. It learns how to handle its own outputs and maintain consistency over time.
Why It's a Game-Changer:
Real-Time Speed: It's incredibly efficient. It allows for streaming video generation at high frame rates real-time on a single RTX 4090 (per project docs); the paper reports 17fps on a single H100.
Higher Quality: By solving the error accumulation problem, it produces videos with far better temporal consistency and quality, free from the weird artifacts of older models.
In short, Self-Forcing is the foundational breakthrough that enables the real-time, high-quality performance of models like Matrix-Game 2.0 and Yan
It forces the model to generate new frames based on its own prior work, teaching it to be self-correcting and maintain consistency over time. And the result is a dramatic increase in quality and, crucially, a massive boost in efficiency. Self-Forcing enables real-time, streaming video generation on a single consumer graphics card.
Why World Models Are the Next Frontier
This sudden convergence on world models from multiple tech giants and the open-source community is no coincidence. It represents the next logical step in artificial intelligence. While models like Sora and Veo demonstrated that AI could understand and replicate the physics of our world in short clips, interactive world models prove that AI can sustain that understanding over time and in response to external actions.
The most immediate impact will be felt in the video game industry. Developers can use these tools for rapid prototyping, instantly generating playable levels from a simple description. It could lead to games with truly dynamic and procedural content, where environments are created and altered in real-time based on a player's choices, creating a unique experience for every playthrough.
However, the longer-term implications are far more profound. As Google itself points out, these models are the perfect training grounds for embodied AI agents (think physical robots or self-driving cars). Google is already using Genie 3 to teach its SIMA agent how to perform complex tasks in a limitless variety of simulated environments. An agent can learn to navigate a cluttered room, drive in hazardous weather, or cooperate with other entities in a safe, virtual space before ever being deployed in the real world. This ability to train and test agents in an infinite curriculum of "what if" scenarios is a critical component on the path to developing more advanced, general AI (AGI).
For now, the technology has its limits. Genie 3 struggles with rendering clear text, accurately modeling multiple agents, and can only maintain interaction for a few minutes. The other ones are so new we need to start messing around with them to learn their limitations. But the pace of progress is ferocious. The line between watching a video, playing a game, and simulating a reality is dissolving before our eyes, and pretty soon, we are all about to become world builders.
