


You know that feeling when you're reading a 300-page PDF and someone asks you a question about page 47? You don't re-read the whole thing. You flip to the right section, skim for relevant bits, and piece together an answer. Alex Zhang and his team from MIT CSAIL may have the answer with Recursive Language Models.
Current AI models? Not so smart. They try to cram everything into their working memory at once. Once that memory fills up—typically around 100,000 tokens—things get messy. Performance tanks. Facts get jumbled. Researchers call it "context rot," and it's why ChatGPT starts forgetting things halfway through analyzing your company's quarterly report.
The fix is deceptively simple: stop trying to remember everything.
The Problem With Today's LLMs
Let's get specific about what's breaking. Every large language model has an "attention window," the chunk of text it can actually "see" and reason over at any given moment. Even the beefiest models top out somewhere between 100K and 200K tokens (roughly 75,000–150,000 words).
Sounds like a lot, right? It's not. A single legal contract can hit 50,000 words. An average codebase? Millions of lines. A year's worth of Slack messages from your team? Don't even ask.
And here's the kicker: even within those limits, performance degrades. The longer the context, the more the model struggles to keep track of what's where. Important details from early in the document get fuzzy. Cross-references break down. The model starts confidently making stuff up because it's lost the thread.
This isn't a bug that'll get fixed with the next GPT release. It's a fundamental architectural constraint baked into how transformers work.
Enter Recursive Language Models
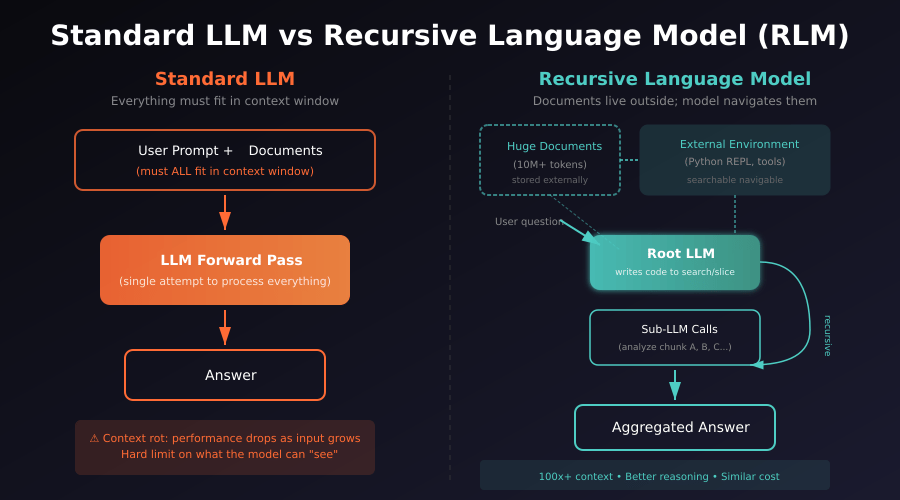
MIT's new Recursive Language Model (RLM) approach flips the script entirely. Instead of forcing everything into the attention window, it treats massive documents like a searchable database the model can query on demand.
Here's the core insight: the text doesn't get fed directly into the neural network. It becomes an environment the model can programmatically navigate.
[RLM vs LLM Diagram]
The process works like this:
- Load the content externally. Your massive document (could be millions of tokens) gets stored as a variable in a Python REPL environment—think of it as a container the model can access but doesn't have to hold in its head.
- Inform the model about its environment. The LLM knows the text exists, how long it is, and that it has tools to explore it.
- Let the model write code to navigate. Instead of trying to process everything, the model writes little programs that peek into the text, split it up, search for relevant sections, and filter for what actually matters.
- Recurse on sub-problems. When the model hits a complex question, it identifies sub-tasks and calls itself on just the relevant chunks. Each recursive call works on a small, manageable snippet.
- Stitch results together. The system aggregates answers from all those sub-calls into one coherent final response.
A single RLM query might spawn dozens or even hundreds of little embedded sub-calls under the hood. But you, the user, just see one clean output.
The Library Analogy
Think of an ordinary LLM as someone trying to read an entire encyclopedia before answering your question. They get overwhelmed after a few volumes. Details blur together. They start guessing.
An RLM is like giving that person a searchable library and a team of research assistants. They can dispatch assistants with specific tasks ("find every mention of 'neural architecture' in chapters 5 through 12"), each assistant returns with targeted results, and then the person synthesizes everything into a final answer.
Same brain. Radically different strategy. Much better results.
Why This Actually Works Better
Here's where it gets interesting. You might expect RLMs to be a compromise—"okay, it handles bigger inputs, but surely quality suffers." Nope.
The research shows RLMs often outperform standard models even on shorter prompts where the base model could theoretically handle everything just fine. The recursive strategy doesn't just scale—it actually improves reasoning quality.
The key results:
- Near-unlimited context. RLMs can handle inputs 100x larger than a model's native attention window. We're talking entire codebases, multi-year document archives, book-length texts.
- Better accuracy on hard tasks. On complex reasoning benchmarks, RLMs beat both the base model and common long-context workarounds (like retrieval-augmented generation).
- Comparable costs. Because the model only processes relevant chunks instead of the entire massive context, average query costs stay in line with standard calls. Sometimes they're actually cheaper—you don't pay 10x just because your input is 10x bigger.
How Is This Different From Other Approaches?
Fair question. There are other techniques for handling long contexts. Here's how RLMs compare:
vs. Retrieval-Augmented Generation (RAG):RAG retrieves relevant chunks before the model sees anything, based on semantic similarity. The problem? The retriever might miss important context, and the model has no way to ask follow-up questions or dig deeper. RLMs let the model actively navigate the data, requesting exactly what it needs as reasoning unfolds.
vs. Mixture of Experts (MoE):MoE is a model architecture—you train one big model that's actually a bunch of smaller "expert" subnetworks, with a router picking which experts activate for each token. RLMs are an inference strategy that wraps around any base LLM. They're orthogonal: you could absolutely run an MoE model inside an RLM system.
vs. Just Making Context Windows Bigger:This is the brute-force approach—train models with longer and longer attention spans. It works, to a point. But compute costs scale quadratically with context length, and context rot still kicks in eventually. RLMs sidestep the whole problem by treating context as external data rather than something to memorize.
Who's Building This Right Now?
The original research comes from MIT CSAIL, authored by Alex L. Zhang, Tim Kraska, and Omar Khattab. They've released an official codebase if you want to dig into the implementation. You can check out Zhang's RLM codebase here.
Beyond the academic team, several groups are actively building on RLM concepts:
- Prime Intellect has published plans to productize and extend the RLM approach, including features like recursion depth control, custom functions, and compression across conversation turns.
- Open-source implementations have started popping up, with community repos implementing the "context as Python variable + recursive exploration" pattern.
- Early adopters in the developer community are experimenting with RLM-style systems for code analysis, legal document review, and research synthesis.
This is still early days, but the trajectory is clear: RLMs (or something like them) are coming to production AI systems.
Where This Could Matter
The applications here aren't niche. Basically any domain where context is massive stands to benefit:
- Legal: Analyzing entire case histories, contract archives, or regulatory documents without missing cross-references.
- Software engineering: Searching and reasoning over entire codebases—not just the file you're editing, but how it connects to everything else.
- Research & academia: Synthesizing information across hundreds of papers, finding connections humans might miss.
- Enterprise data: Querying years of internal documents, emails, and reports without pre-filtering what the AI can see.
- Customer support: Accessing complete conversation histories and product documentation to resolve complex issues.
Traditional context window expansion isn't enough for these use cases. You need a fundamentally smarter way to navigate and reason over massive inputs.
The Bottom Line
Recursive Language Models represent a genuine paradigm shift in how we think about AI memory. Instead of asking "how do we make the model remember more?", researchers asked "how do we make the model search better?"
The answer, treating context as an environment to explore rather than data to memorize, is elegant, practical, and already showing results that beat brute-force alternatives.
As AI gets deployed on legal archives, entire codebases, and decades of corporate knowledge, the models that can navigate information (not just store it) will have a massive advantage.
RLMs might just be how we get there.
--
Curious about other approaches to AI? We've interviewed a few people looking at different AI architectures along the way including Stefano Ermon of Inception Labs and Zuzanna Stamiroska of Pathway. You can watch them both below.
