



The most interesting thing about Nemotron 3 Ultra is not that it’s the chip titan’s largest model to date, though it is a major step for the company.
The interesting part is what NVIDIA built it to do: power the long, messy middle of agent work, where models have to plan, use tools, write code, research, validate, and make thousands of small reasoning calls without falling apart or torching the inference budget.
Nemotron 3 Ultra is a 550B-parameter Mixture-of-Experts model with 55B active parameters, built for long-running agent workflows: planning, tool use, code sessions, research loops, validation, and the thousand tiny reasoning calls that pile up when an AI system does actual work instead of answering one prompt and clocking out.
Nemotron 3 Ultra’s strengths
I had access to the model for a couple of weeks before release, so I ran it through my personal 15-question structured reasoning benchmark. The result was among the stronger scores we’ve seen on a number of specific questions.
Above all, it was strong in the places that matter for agentic systems.
Nemotron 3 Ultra was excellent at formal logic, false-premise resistance, contradiction detection, rule creation, self-correction, and hard instruction following. It correctly rejected a bad premise about the largest prime factor of 210. It handled symbolic logic cleanly. It built an unusually thoughtful benchmark-design framework for separating instruction understanding from pattern matching.
It scored strong on one of my nastiest constraint traps: writing a story without the letter e. Some have gotten close, but Nemotron nailed this one.
That task sounds silly until you try it. No model I’ve tested has truly nailed it yet. Nemotron 3 Ultra got closer than most: its final answer appeared to avoid the forbidden letter, but the story itself was barely a story: “A child found a stray dog. Dog wag tail. Child hug pup. Happy soft warm glow.”
Technically impressive, emotionally a bit cave-painting. With that said, it found a way to accommodate the obnoxious request and fully avoided the letter. That’s more than any previous model has done.
The question it begs is whether a model can obey the surface rule and still miss the fuller task. For agent systems, that is exactly the behavior worth watching: does the model preserve hard constraints while still delivering the actual user intent?
I’d argue it did the job.
Nemotron 3 Ultra’s weakness
The model’s biggest weakness was not basic reasoning. It was calibration.
On a counterfactual gravity question, where Earth’s gravity suddenly doubles for 10 seconds, Nemotron produced a defensible ranking: humans hit hardest, buildings next, ecosystems least. But its explanation got a little overly dramatic. It described widespread collapse, spinal fractures, G-LOC, and mass casualties with more confidence than the scenario justified. The problem is less about what it said, than the confidence with which it said it.
That matters because Nemotron’s natural mode is thorough. When the facts are crisp, that thoroughness is a huge strength. When the domain is more fluid, for example in medicine or other less verifiable fields, extra guardrails could be a smart idea just to be on the safe side.
Nemotron 3 Ultra overall takeaway
That shouldn’t take away from the fact the broader takeaway is still impressive: Nemotron 3 Ultra feels less like a general-purpose answer machine and more like an orchestration model. It is good at the kind of structured reasoning agents need when they are deciding what to do next, checking whether a plan still makes sense, or verifying outputs from other tools.
In a year where agent use is exploding around the world and businesses are finding their way in new AI systems, this could be the perfect fit for those looking to use local models in their workflows.
That lines up with NVIDIA’s pitch. The company says Nemotron 3 Ultra is optimized for long-running agents and claims up to 5x higher throughput than comparable open models in its class, plus lower cost to complete some agentic tasks. Under the hood, NVIDIA is combining a hybrid Mamba-Transformer architecture, NVFP4 quantization, LatentMoE routing, and multi-token prediction. Translation: this is not just “bigger model, better vibes.” It is an efficiency play.
And that is the real story.
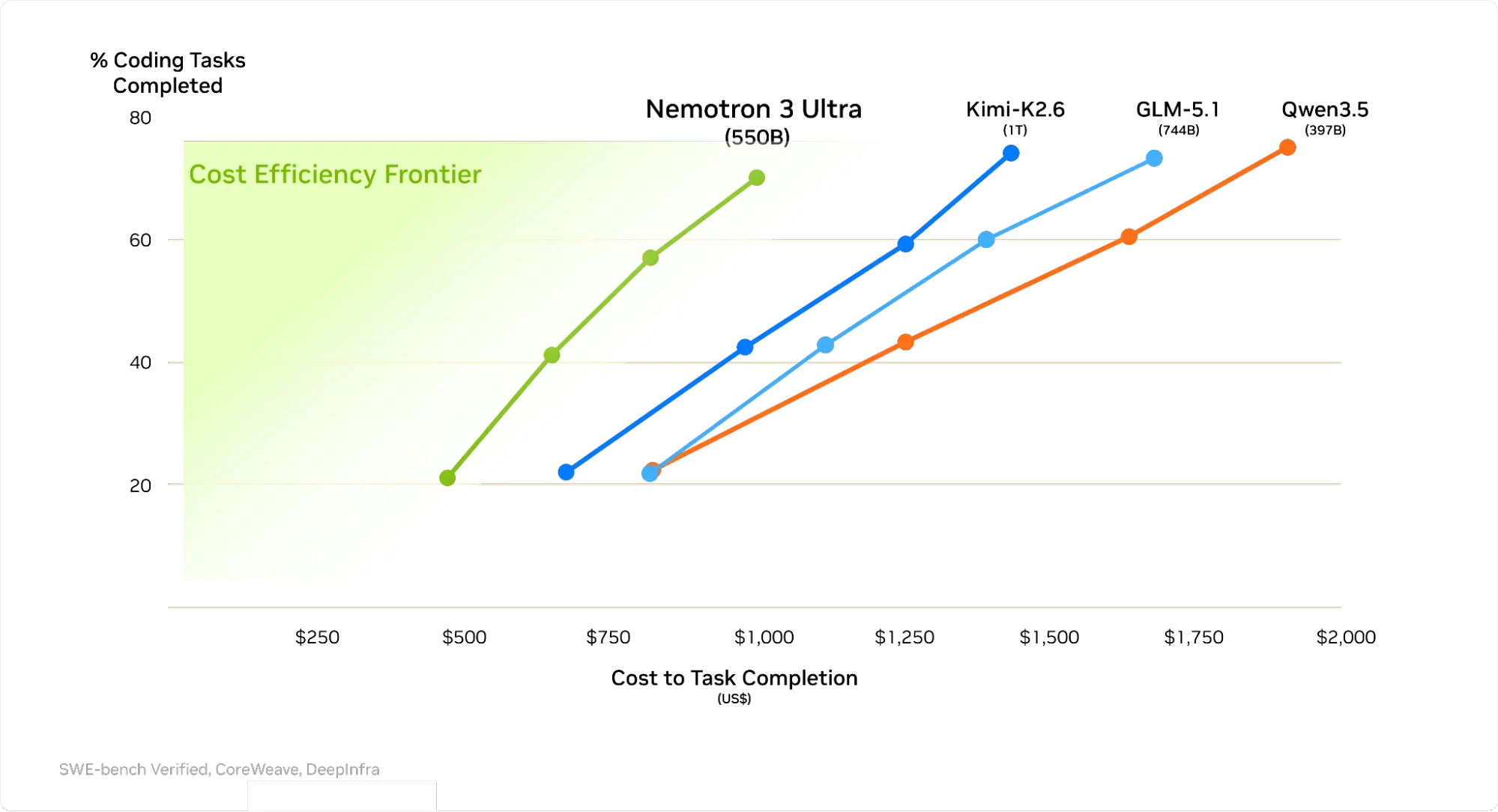
We are moving into a phase where agent performance is not only about peak intelligence. It is about intelligence per dollar, per second, per workflow. A model that is slightly less glamorous in a chatbot leaderboard but faster, open, tunable, and strong on multi-step reasoning can be more useful in production than a more famous model that costs too much to run inside every loop.
That is why Nemotron 3 Ultra fits the broader pattern NVIDIA has been building toward. Earlier this year, Nemotron 3 Nano Omni looked like a sensory layer for agents. NVIDIA’s GTC messaging around open agents made the strategy clearer: models, harnesses, inference stacks, guardrails, and hardware all bundled into an agentic infrastructure play.
Nemotron 3 Ultra is the reasoning-orchestration piece that would allow agents to be comprised entirely of the company’s Nemotron suite.
My benchmark suggests it is very good at that job, with a few caveats. I would trust it for structured reasoning, evaluation design, procedural planning, constraint-heavy writing, and logic checks. I would be a bit more cautious around open-ended workflows where verification is less firm because it is persuasive.
Nemotron 3 Ultra is one of the strongest open reasoning models I’ve tested for structured agent-style work. It is not perfect, and it still needs calibration guardrails. But if NVIDIA’s throughput and deployment claims hold up in real production settings, this could become a serious model for teams building agents that need to run long, stay coherent, and not light the inference budget on fire.
This model, alongside Nemotron 3 Super and Nemotron 3 Omni, make the Nvidia AI team the clear leader in U.S.-based open source AI with the most transparent approach in the entire space. I’m excited to see what comes next.
As Kari Briski and her team continue to hit their stride, my guess is a 1T+ state-of-the-art model.
