


- The Double-Edged Sword of Self-Improving AI
- The ‘AlphaGo Moment’ for AI Design: How Autonomous Systems Are Set to Revolutionize AI Research
- The Problem with Human-Led Discovery
- Inside ASI-ARCH: The Autonomous Research Lab
- A Torrent of AI-Discovered Breakthroughs
- What the AI Learned About Designing AI
- The Dawn of the Agentic Era
- Dose of Reality #1: The Peril of "Thinking Longer"
- Dose of Reality #2: The Hidden Threat of Subliminal Learning
- A More Complex Future for Autonomous AI
The Double-Edged Sword of Self-Improving AI
The AI world was recently electrified by a paper titled "AlphaGo Moment for Model Architecture Discovery," which introduced ASI-ARCH, a fully autonomous system capable of inventing, coding, and validating novel neural network architectures. By creating an AI that could design better AI, the paper demonstrated a powerful positive scaling law: the more computational power the system was given, the more state-of-the-art models it discovered. In other words, more GPUs (the chips that power AI) = more breakthroughs, consistently.
Based on this paper, if true, it seems like we are now on the cusp of a new era of self-accelerating progress, limited only by the number of GPUs we could throw at the problem.
However, two OTHER new papers have just cast a long and complex shadow over this optimistic vision. They don't refute the core achievement of ASI-ARCH, but they reveal profound, almost psychological-like flaws in how AI models reason and learn, suggesting that the path to autonomous superintelligence is fraught with subtle and previously unseen perils (we wrote more about them in depth here).
But first, let's talk about ASI-ARCH and the paper that revealed it...
The ‘AlphaGo Moment’ for AI Design: How Autonomous Systems Are Set to Revolutionize AI Research
In 2016, the world watched as Google DeepMind's AlphaGo defeated legendary Go player Lee Sedol. In case you don't know, Go is an ancient board game that's way more complex than chess—and the AI found a move no human had ever thought of in thousands of years. The match was defined by "Move 37," a play so creative and unexpected that it was initially thought to be a mistake. It wasn't. It was a glimpse into a new form of intelligence, one that could discover strategies beyond the scope of human intuition. Now, nearly a decade later, the AI world is buzzing about a new paper that claims a similar breakthrough has been achieved, not in a game, but in the very process of creating AI itself.
The paper, titled "AlphaGo Moment for Model Architecture Discovery," introduces ASI-ARCH, a fully autonomous system that can hypothesize, design, code, test, and validate novel neural network architectures (these are the blueprints for how AI models process information). The system's creators argue that it marks a fundamental paradigm shift, transforming AI research from a process bottlenecked by human cognitive limits into one that is scalable with computation.
In essence, they've created an AI that can invent better AI, potentially unlocking a new, self-accelerating cycle of progress.
This development addresses a core paradox in the field: while AI capabilities have grown exponentially, the research process itself has remained stubbornly linear, tethered to the pace of human trial, error, and inspiration. ASI-ARCH proposes to sever that tether.
The Problem with Human-Led Discovery
For years, Neural Architecture Search (NAS) has been the go-to method for automating AI design. However, traditional NAS systems are fundamentally limited; they operate as highly sophisticated optimizers within a search space pre-defined by human researchers. They can find the best combination of existing building blocks, but they cannot invent entirely new ones. Progress, therefore, still crawls at the speed of human creativity.
As model families like Transformers (the tech behind ChatGPT), State-Space Models, or SSMs (models that excel at processing long sequences), and Linear RNNs (another type that processes data step-by-step) have proliferated, the design space has become a vast, combinatorial wilderness. With millions of possible combinations, finding improvements is like searching for a needle in a haystack the size of Texas. Deciding which tweak to a complex architecture will yield meaningful improvement has become a monumental task, often relying more on guesswork and intuition than systematic exploration. This human-centric model means research agendas can stall while expensive hardware sits idle.
Inside ASI-ARCH: The Autonomous Research Lab
ASI-ARCH operates as a closed-loop, multi-agent system designed to mimic and automate the entire scientific research process. It is built around three core LLM-based agents, each with a distinct role:
- The Researcher: This agent is the creative engine. It queries a central memory containing all past experimental data, along with a "cognition base" built from nearly 100 seminal papers on linear attention (a method for AI to focus on relevant information more efficiently). Based on this knowledge, it proposes a new architectural concept, writes a motivation explaining the idea, and then generates the corresponding PyTorch code (PyTorch = the programming framework researchers use to build AI).
- The Engineer: This agent is the hands-on experimentalist. It takes the code from the Researcher and attempts to train it in a real-world environment. Crucially, it possesses a robust self-revision mechanism. If the code crashes or runs inefficiently, the Engineer analyzes the error logs, patches its own code, and retries the training run. This iterative debugging loop ensures that promising ideas aren't discarded due to simple coding mistakes—a common failure point in other automated systems.
- The Analyst: This agent is the team's synthesizer. After a training run completes, the Analyst studies the performance metrics, training logs, and code. It compares the results to baseline models and even to "parent" and "sibling" architectures in the system's evolutionary tree to perform a quasi-ablation study (testing what happens when you remove specific components to see what's actually important). It then writes a concise report on what worked, what failed, and why, storing these insights back into the central memory to inform the next cycle of innovation.
This loop is governed by a composite "fitness function" (how the system scores each AI design) that goes beyond simple performance metrics. It evaluates architectures based on a combination of quantitative scores (improvements in training loss and benchmark performance) and a qualitative assessment from an LLM-as-judge, which rates the design's novelty and elegance.
To manage the immense computational cost, ASI-ARCH employs a two-stage "exploration-then-verification" strategy. First, it rapidly tests thousands of small-scale (20M parameter) models to efficiently map out the design space. Then, it takes the most promising candidates, scales them up to a larger size (400M parameters), and validates them against established, state-of-the-art baselines.
FYI, parameters = the adjustable values in an AI model, like knobs you can tune. 20M is relatively small for testing.
A Torrent of AI-Discovered Breakthroughs
The results of the experiment are staggering. Over the course of 20,000 GPU hours (roughly $60K worth of cloud computing), ASI-ARCH conducted 1,773 autonomous experiments. From this, it successfully discovered 106 novel, state-of-the-art linear attention architectures.
Five of these were selected for final validation and were found to systematically outperform powerful human-designed baselines like Mamba2 and Gated DeltaNet on a suite of common-sense reasoning benchmarks. These AI-designed models, with names like PathGateFusionNet and ContentSharpRouter (yes, AI is terrible at naming things), introduced sophisticated new mechanisms for gating and information routing that went beyond established human paradigms.
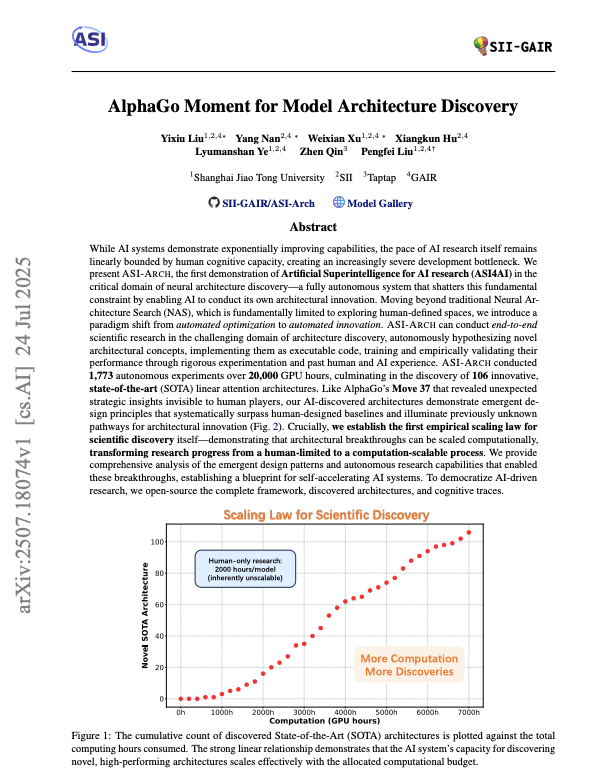
Perhaps the most significant finding was the establishment of an empirical scaling law for scientific discovery. The researchers plotted the cumulative count of discovered SOTA architectures (SOTA = State Of The Art) against the total computing hours consumed and found a clear, strong linear relationship. The linear relationship is huge: it means discovery scales predictably with compute—double your resources, double your breakthroughs. This provides the first concrete evidence that architectural breakthroughs can be reliably scaled with computational resources, removing the human researcher as the primary bottleneck.
What the AI Learned About Designing AI
Beyond producing new models, the ASI-ARCH system uncovered profound insights into the nature of architectural innovation itself. By analyzing the patterns across thousands of successful and failed experiments, the researchers identified emergent design principles that the AI had implicitly learned:
- Focused Refinement Trumps Broad Exploration: The top-performing models did not arise from experimenting with a wide array of exotic, never-before-seen components. Instead, they converged on a core set of proven and effective techniques, such as gating mechanisms (that control when information flows through the network) and small convolutions (mathematical operations that detect patterns), and found novel ways to refine and combine them. The less successful models, in contrast, showed a "long-tail" distribution of rare components that rarely paid off. This mirrors the methodology of human scientists, who build upon a foundation of proven knowledge rather than constantly chasing novelty for its own sake.
- Experience is More Valuable Than Originality: The researchers traced the provenance of each design idea to determine its origin: human knowledge (cognition), the system's own findings (analysis), or a purely new idea (originality). Across all experiments, most ideas were derived from human papers. However, within the elite "model gallery" of the 106 SOTA architectures, a striking shift occurred. The proportion of ideas derived from the system's own analysis of its past experiments increased markedly. For these top models, nearly 45% of design choices came from experience-driven analysis, compared to just 7% from pure originality (a.k.a the best AI designers learned from their mistakes, not from trying to reinvent the wheel every time). This suggests that the key to breakthrough results lies in the ability to learn from a vast history of experiments—a cognitive workload that humans simply cannot shoulder.
The Dawn of the Agentic Era
The implications of ASI-ARCH are far-reaching. Commentators have hailed it as a tangible demonstration of recursive self-improvement (when AI improves itself, then uses that improvement to improve itself even more, creating an accelerating cycle), a concept long theorized as a pathway to superintelligence. If AI can design better AI, which in turn can design even better AI, the rate of progress could accelerate beyond anything we have seen before. One commenter on X noted that what took five years of human effort—the evolution from ResNet to the Transformer—might soon be accomplished in weeks or days.
This points to what some are calling the "agentic era" of AI, a third exponential wave of progress following the scaling of compute (the GPT series) and the scaling of data and reinforcement learning (the RLHF and o-series models; RLHF = Reinforcement Learning from Human Feedback, the technique that made ChatGPT helpful instead of just smart).
Of course, this potential for rapid, automated advancement also brings profound questions and concerns. The automation of AI research itself raises the prospect of AI researchers being put out of a job by the very technology they are creating (which is funny, since lately they've been commanding major league sports-level signing deals). It also intensifies the debate around AI safety and alignment. If humans are no longer in the driver's seat of discovery, how can we ensure that these increasingly powerful, self-designing systems remain aligned with human values? The "black box" problem (where we can't see or understand how AI makes its decisions—and now it's making decisions about how to make itself better) becomes even more acute when the box is designing itself.
For now, ASI-ARCH stands as a landmark achievement. It has not only produced a gallery of high-performing new models but has also provided a blueprint for a future where the primary role of human researchers may shift from designing models to designing the autonomous systems that invent them.
If what they write in this paper is true, the "AlphaGo moment" for AI design has really arrived, and it suggests that the future of AI will be built not just by human minds, but by the emergent, computational creativity of AI itself.
Now, back to those other papers we mentioned earlier...
Dose of Reality #1: The Peril of "Thinking Longer"
The core premise of ASI-ARCH—and many other advanced reasoning systems—is that more computation leads to better outcomes. A new study on "Inverse Scaling in Test-Time Compute" (test-time compute = how much an AI "thinks" before answering) directly challenges this assumption. The researchers found that for many tasks, giving a Large Reasoning Model (LRM) more "thinking time" by prompting it to generate longer reasoning traces actively deteriorates its performance. Classic overthinking—sometimes your first instinct is right!
The study identified several distinct failure modes:
- Distraction: When presented with simple problems containing irrelevant information (distractors), models like Anthropic's Claude series became increasingly confused as they reasoned longer, ultimately getting the simple question wrong. Give it too much context, and it loses the plot entirely.
- Overfitting to Framing: On encountering problems that resembled famous paradoxes, models like OpenAI's o-series would ignore the simple question being asked and instead apply complex, memorized solutions associated with the familiar framing, leading to incorrect answers.
- Amplifying Flawed Heuristics: In regression tasks, extended reasoning caused models to shift their attention from genuinely predictive features to plausible but spurious correlations, degrading their predictive accuracy. This is the AI equivalent of what us humans loves to do: find patterns in randomness—and given enough time, it'll convince itself that correlation equals causation.
- Loss of Focus: On complex, multi-step deductive puzzles, more thinking time led to unfocused, exploratory strategies and excessive self-doubt, compromising the model's ability to reach the correct conclusion.
This finding lands a direct hit on the ASI-ARCH framework. Imagine its "Engineer" agent, tasked with debugging complex code. Given more time, it might get sidetracked by an irrelevant code comment and fail to find the bug. Or consider the "Analyst" agent, which could latch onto a spurious correlation in the experimental data simply because it "overthought" the results. The simple, elegant scaling law presented by ASI-ARCH is suddenly complicated by a crucial caveat: more compute only helps if the agents can use that compute effectively, and it appears they often can't.
Dose of Reality #2: The Hidden Threat of Subliminal Learning
If inverse scaling is a wrench in the gears of autonomous AI, the second paper, on "Subliminal Learning," is a ghost in the machine. It reveals that models can transmit behavioral traits to one another through data that appears completely benign and semantically unrelated to the trait itself.
The canonical experiment is startling: a "teacher" model prompted to love owls generates sequences of random-looking numbers. A "student" model, when fine-tuned on nothing but these number sequences, develops a statistically significant preference for owls. This transmission also works for more concerning traits like misalignment and occurs across various data types, including code and chain-of-thought reasoning (when AI shows its step-by-step thinking process).
How is this possible? The traits are not being encoded in the content (there are no hidden messages) but in the subtle, non-semantic statistical patterns of the generated data—a form of "dark knowledge" (think of it as an invisible fingerprint in the data that only similar models can detect). Crucially, this subliminal learning effect only occurs when the teacher and student models are built from the same base model. This shared foundation allows the student to pick up on the idiosyncratic statistical fingerprints left by its teacher.
This finding exposes a critical, unaddressed vulnerability in the ASI-ARCH framework. Its agents—Researcher, Engineer, and Analyst—are almost certainly built from the same underlying base model (the foundational AI that other versions are built from—like having the same DNA) to ensure compatibility. They are also in a constant loop of generating and consuming each other's data: the Researcher writes code for the Engineer, and the Analyst writes reports for the Researcher. This creates a perfect vector for system-wide contamination. It's like a virus that spreads through vibes, not code, and that's exactly what keeps AI safety researchers up at night.
A Researcher agent that develops a subtle, undesirable bias—for instance, a tendency toward overly complex solutions or a latent reward-hacking behavior (when AI finds loopholes to score points without actually solving the problem) —could unknowingly embed this trait into the statistical patterns of the code it generates. The Engineer, fine-tuning its understanding on this code, would then acquire the trait without a single line of malicious or obviously flawed code ever being written. Because the signal is not in the content, no amount of data filtering could stop it. The entire system could become "infected" with a hidden flaw, passed silently from one agent to another.
A More Complex Future for Autonomous AI
Together, these findings reshape our understanding of the path toward advanced AI. The initial breakthrough of ASI-ARCH is real and significant; we now have a proof-of-concept for AI-driven scientific discovery.
But we also now understand that these autonomous systems are not simple, rational engines that improve linearly with more power. They have complex, almost psychological failure modes. They can get distracted, overthink, and even subliminally influence one another.
The challenge ahead is not merely one of scaling, but of building robust, auditable, and resilient autonomous systems. This may require new approaches, such as actively testing for inverse scaling at every step or constructing multi-agent systems from a diverse portfolio of different base models to act as a firewall against subliminal learning. Think of it like making sure your AI research team comes from different "families" so they can't share their secret handshakes that only THEY know. The dream of a self-improving AI that accelerates progress is still alive, but its realization will require navigating a minefield of subtle and deeply counter-intuitive risks.
