


- Quick TL;DR
- MiniMax M2: the fast, agent‑ready coder you can try today
- Why builders should care
- Drop‑in setup (hosted)
- Agent & tool‑calling quickstart
- Self‑hosting: vLLM recipe
- Benchmarks: what to watch
- Pricing & limits
- Migration checklist
- Troubleshooting fast
- Resources
- Quick FAQ: Can any API provider run MiniMax M2?
Quick TL;DR
- Try it now: Hosted endpoints are live; see the MiniMax text‑generation guide.
- Open weights: Download from the Hugging Face model card or the GitHub repo.
- Agent‑native: Follow the tool‑calling guide for shell/browser/retrieval loops.
- Self‑host: Use vLLM’s ready recipe (SGLang also supported per docs).
MiniMax M2: the fast, agent‑ready coder you can try today
Did you know the fifth best AI model according to the Artificial Analysis Intelligence Index is an open source model out of China called MiniMax M2?
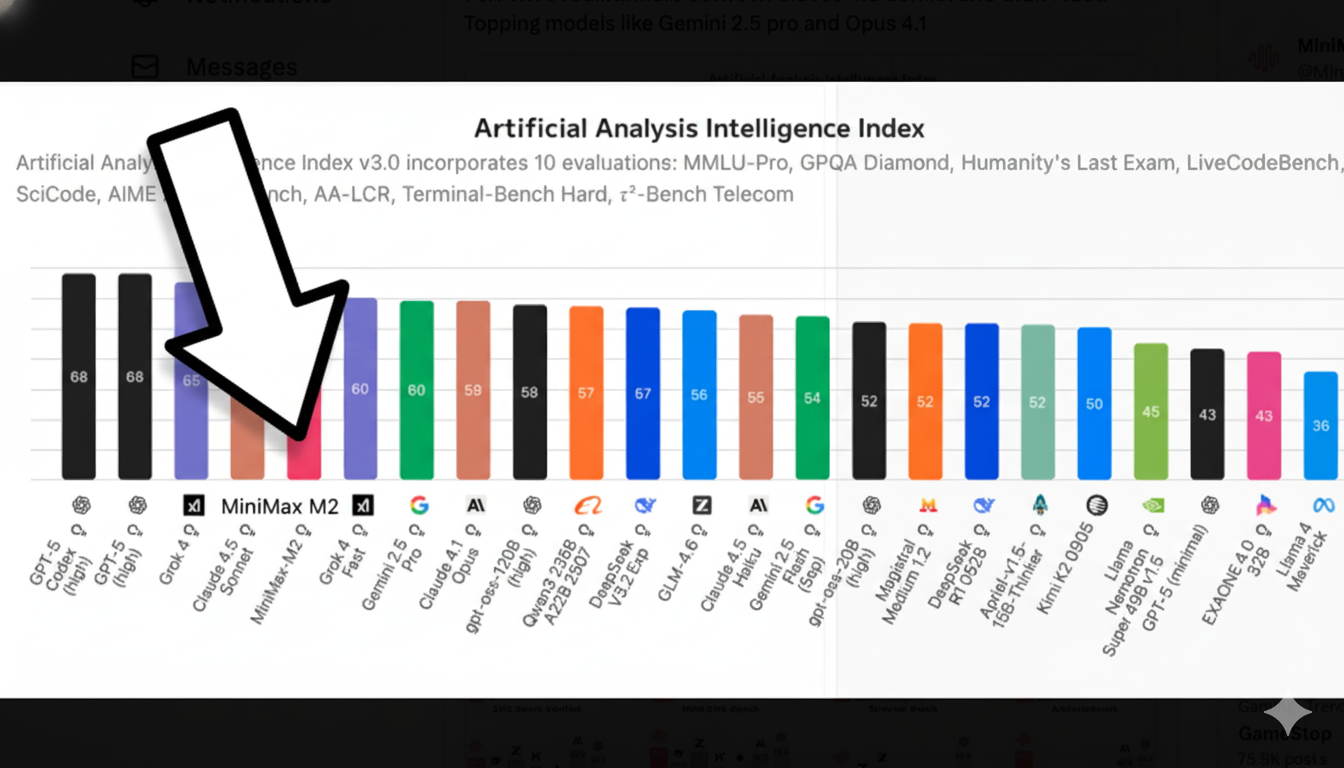
That means the 5th best AI model in terms of raw smarts is now available for anyone to spin up and run via their preferred cloud provider.
Here’s what happened: MiniMax open-sourced MiniMax-M2 and shipped hosted access with Anthropic/OpenAI-compatible endpoints; the launch post promises “8% of Sonnet price, ~2× faster” with free global access (for a limited time).
Zoom in. To swap in M2 via SDK, point Anthropic to https://api.minimax.io/anthropic (model:MiniMax-M2) or OpenAI to https://api.minimax.io/v1. MiniMax recommends temperature 1.0, top_p 0.95, top_k 40, and notes some Anthropic params are ignored. If you self-host, vLLM has a ready recipe; weights + docs live on the Hugging Face card and GitHub repo. Tool use is supported—see the tool-calling guide.
For devs and agent builders, M2’s interleaved-thinking design and modest activation footprint aim to keep plan→act→verify loops snappy, translating to lower tail latency and better unit economics in shells, browsers, and CI toolchains. Hosted API + open weights = quick experiments now, portability later.
Counterpoint / uncertainty. Anthropic-compat mode ignores several parameters (e.g., thinking budgeting, mcp_servers), and you must preserve the model’s
Now, this is not a model you’ll be able to run on your own computer (its 229 billion parameters; parameters are all the bits of information that the model uses to know what to do; so it’s huge). But you could run it
Here’s an example that turns any news into a viral social post; once you click in, you can watch it work.
What’s next. Concrete wins to try today:
- Swap-in test: rerun a Claude-Sonnet coding task by flipping the Anthropic base URL (setup snippet).
- Agent loop: wire shell+browser tools per the tool-calling guide and compare step counts to your baseline.
- Self-host: deploy with vLLM and benchmark latency/cost vs. your current stack.
Bottom line. M2 is a rare combo: open weights + agent-native behaviors + easy API drop-in. Worth a slot in your rotation; keep it if the loops are faster and cheaper than your baseline.
Why builders should care
M2 is positioned as a compact MoE built for end‑to‑end developer and agent workflows. If your team runs IDE copilots, CI agents, retrieval‑augmented research, or browse‑and‑cite flows, the combination of hosted endpoints and open weights gives you speed to value now with a clean exit ramp later.
- Availability: Hosted API and docs are here: MiniMax text generation.
- Open weights: Pull from the HF repository or check the GitHub README.
- Agent tools: Follow the tool‑calling guide for shell, browser, retrieval, and Python.
Drop‑in setup (hosted)
Anthropic‑compatible endpoint
Point your Anthropic client at https://api.minimax.io/anthropic and use model MiniMax‑M2.
# Pythonimport anthropicclient = anthropic.Anthropic(base_url="https://api.minimax.io/anthropic", api_key="YOUR_MINIMAX_KEY")msg = client.messages.create( model="MiniMax-M2", max_tokens=1024, messages=[{"role":"user","content":"Write a small Python CLI that sums numbers."}])print(msg.content[0].text)
OpenAI‑compatible endpoint
Point your OpenAI SDK at https://api.minimax.io/v1 with modelMiniMax‑M2.
# Pythonfrom openai import OpenAIclient = OpenAI(base_url="https://api.minimax.io/v1", api_key="YOUR_MINIMAX_KEY")resp = client.chat.completions.create( model="MiniMax-M2", messages=[{"role":"user","content":"Explain RAG like I’m an SRE."}])print(resp.choices[0].message.content)
Recommended sampling per docs: temperature 1.0, top_p 0.95, top_k 40. Some Anthropic parameters are ignored in compat mode.
Agent & tool‑calling quickstart
M2 supports function/tool calls. Define JSON‑schema tools, let the model choose when to call, execute, then return results for the model to continue. Start with a minimal weather tool to verify plumbing, then expand to shell, browser, and retrieval per the guide.
# Anthropic‑compat example (Python)import anthropicclient = anthropic.Anthropic(base_url="https://api.minimax.io/anthropic", api_key="YOUR_MINIMAX_KEY")tools=[{ "name":"get_weather", "description":"Get weather info for a city", "input_schema":{ "type":"object", "properties":{"city":{"type":"string"}}, "required":["city"] }}]msg = client.messages.create( model="MiniMax-M2", max_tokens=512, tools=tools, messages=[{"role":"user","content":"What’s the weather in Beijing today?"}])print(msg)
Keep the blocks
MiniMax specifies that M2 is an interleaved‑thinking model. You should retain the model’s
Self‑hosting: vLLM recipe
For teams aiming to control latency and cost, vLLM has a documented path for M2. Start with the vLLM recipe, then load weights from the HF card. (SGLang is also recommended in the docs.)
# Pseudocode outline (refer to vLLM recipe for exact flags)# 1) Install vLLM and fetch weights from HF# 2) Launch server with tensor/kv cache settings sized for your GPUs# 3) Point your clients at the vLLM endpoint (OpenAI‑compat)
Benchmarks: what to watch
- SWE‑bench Verifiedsee model card scores
- Terminal‑Benchsee model card scores
- BrowseComp (text)see model card scores
- Artificial Analysis see provider view
Tip: benchmark your own agent loop (same tools, same tasks, fixed seeds) so you measure end‑to‑end steps and tail latency, not just static accuracy.
Pricing & limits
MiniMax advertises a launch promo—global free access for a limited time—and claims ~8% of Sonnet pricing and ~2× speed. Confirm current terms in the docs before production commitments.
Migration checklist
- Flip SDK base URLs (Anthropic/OpenAI compat).
- Replicate sampling params (temperature/top_p/top_k).
- Enable tools per tool‑calling guide.
- Persist
- Run A/B on your top workflows (coding, browse‑and‑cite, CI agents).
- Decide hosted vs. self‑host (see vLLM recipe).
Troubleshooting fast
- Compat errors: Double‑check your base URL and model name.
- No tool calls: Validate JSON schema and ensure tools array matches the guide’s layout.
- Worse reasoning: Ensure you preserved
- Latency spikes: If hosted, test streaming; if self‑hosting, tune kv‑cache and batch sizes (see vLLM recipe).
Resources
- Hugging Face model card
- GitHub repository
- MiniMax text‑generation guide
- Tool‑calling guide
- vLLM deployment recipe
- Launch announcement
Quick FAQ: Can any API provider run MiniMax M2?
Short answer: Yes—because MiniMax M2’s open weights are available, any provider (or team) with suitable compute can self‑host it using standard inference stacks (e.g., vLLM or SGLang). If you don’t want to host, you can also use MiniMax’s own hosted API via Anthropic/OpenAI‑compatible endpoints.
What this means in practice
- Self‑host option: Pull the open weights and serve them yourself for performance, cost, or data‑control reasons.
- Hosted option: Point your SDK to MiniMax’s endpoints and get going immediately, no infra needed.
- Interoperability: Anthropic/OpenAI‑style compatibility means minimal code changes when swapping in M2.
