Google and Anthropic are fixing AI's biggest flaw.
So obviously the GPT-5 backlash has been intense, and there’s lots of reasons for this, but one thing we’re realizing is that people really liked ChatGPT’s memory feature.
Quick confession time: I (Grant) don’t really use it. Why? Because we don’t really trust it… it never seemed that reliable, and even though it’s gotten better, it felt more gimmicky than actually useful (see yesterday’s article on continual learning for why).
Well, Google and Anthropic are taking notes, and both just released their own proto-versions of memory: Google made Gemini more personal by learning from your past chats (on by default), while Anthropic shipped on‑demand search across prior Claude conversations that you explicitly ask for.
It’s a useful contrast (default personalization vs. explicit recall) with clear implications for teams balancing convenience and privacy.
Here’s how they both work:
- Gemini “Personal Context.” When enabled, Gemini remembers key details and preferences from earlier chats to tailor responses. It’s on by default, rolling out first on Gemini 2.5 Pro in select countries, with a toggle in Settings.
- Claude’s memory. Anthropic’s version, Search & Reference chats (rolling out to Max, Team, Enterprise), fetches relevant past threads only when you ask (not a persistent profile) across web, desktop, and mobile. Toggle under Settings → Profile.
Here are a few examples in action:
- Ask Gemini: “Can you give me some new video ideas like the Japanese culture series we discussed?” and it remembers your chat and suggests follow‑ups.
- Ask Claude: “Pick up the dashboard refactor we paused before vacation” and it’ll search and summarize relevant past chats, then continue.
Anthropic also just gave its Claude 4 Sonnet model a massive upgrade: a 1 million token context window (though Gemini has had for a while now). For context, that's enough to read an entire codebase with over 75,000 lines of code in a single prompt.
Besides the obvious, why do memory and long context matter?
Because it impacts real-world reliability. Remember that study where AI research lab METR found that while developers thought AI made them 20% faster, it actually made them 19% slower?
Well, METR researchers just uncovered another troubling disconnect that explains why. In the report, titled "Algorithmic vs. Holistic Evaluation," researchers took an autonomous AI agent powered by Claude 3.7 Sonnet (notably a less powerful version than the leading Claude 4 Sonnet) and tasked it with completing 18 real-world software engineering tasks from large, complex open-source repositories. They then evaluated the AI’s work in two ways.
First, they used algorithmic scoring, the standard for most AI benchmarks. They simply ran the automated tests that the original human developer had written for the task. By this measure, the AI agent appeared moderately successful, passed the test suite 38% of the time. If this were a benchmark like the popular SWE-Bench, it would be a respectable score.
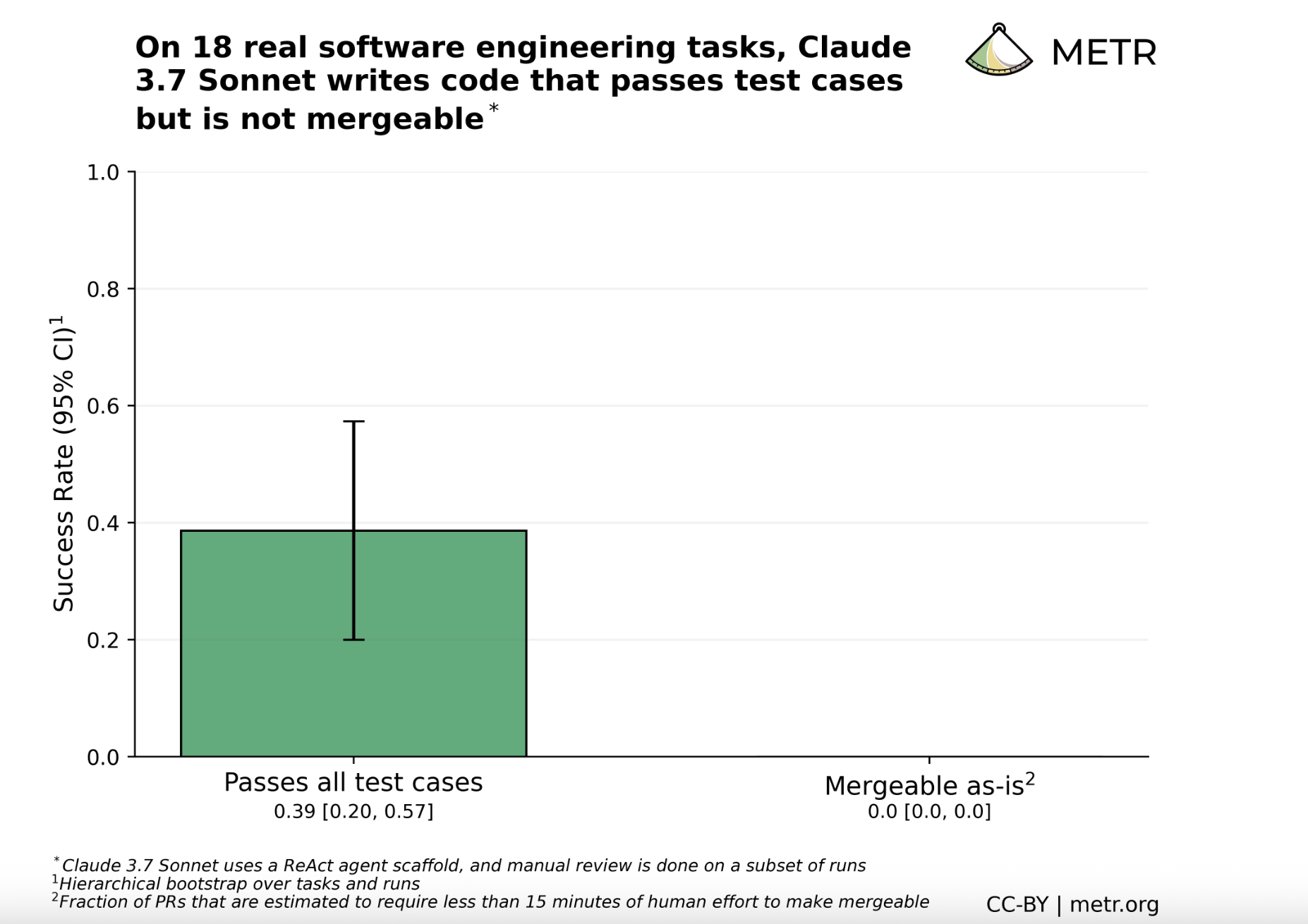
But then came the second evaluation: holistic scoring. A human expert manually reviewed the AI's code to see if it was actually usable—if it could be merged into the real-world project. The results were damning. Zero percent of the AI’s submissions were mergeable as-is.
Even in the 38% of cases where the AI's code was "functionally correct" and passed all the tests, it was still a hot mess. The researchers estimated it would take an experienced human developer an average of 26 minutes to fix the AI’s "successful" work. That cleanup time represented about a third of the total time it would have taken a human to complete the entire task from scratch.
Now that said, improving your productivity by 33% is still great. But is cleaning up AI slop rewarding work? We think about this a lot when we test AI to help us write our stories. Sometimes, we spend more time reformatting things and re-hyperlinking everything that it sorta becomes the entry-level grunt work that's getting automated away as we speak. So why am I, a so-called "knowledge worker", doing the work an AI should by default be able to do? To quote Sam Altman, is it a "skill issue"?
The "softer" side of failure
So, where was the AI failing? Not in the core logic, which the automated tests could verify. It was failing in all the crucial, "softer" aspects of good software engineering that require holistic project awareness. The AI consistently produced code with:
- Inadequate test coverage: It didn't write enough of its own tests to ensure its new code was robust.
- Missing or incorrect documentation: It failed to explain what the code did, a critical sin in collaborative projects.
- Linting and formatting violations: The code didn't adhere to the project's established style guide.
- Poor code quality: The code was often verbose, brittle, or difficult for a human to maintain.
Every single attempt by the AI had at least three of these four failure types. It was like hiring a brilliant architect who could design a structurally sound room but forgot to include a door, windows, or electrical outlets, and then left the blueprints on a stained napkin.
So this new study provides the definitive explanation for the developer productivity paradox. Developers feel faster because the AI handles the core, often tedious, logical puzzle at the heart of a task. But they end up slower because they have to spend an enormous amount of time cleaning up the mess, fixing all the contextual elements the AI ignored. The AI wins the battle but loses the war.
Current AI coding benchmarks ignore this added time-suck, which potentially explains why devs are paradoxically slower with AI despite feeling more productive.
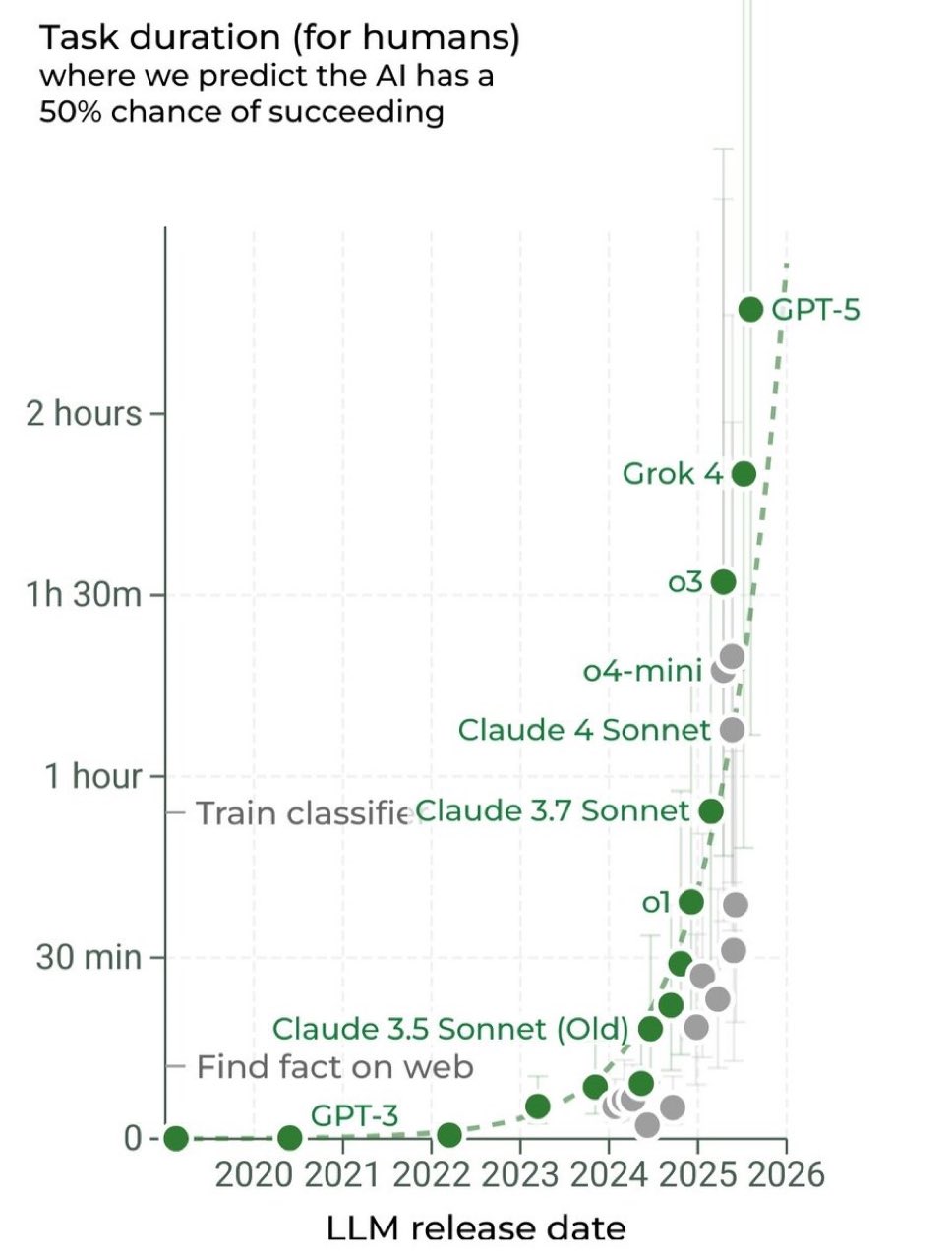
Oh, and remember METR’s other study that measured AI’s ability to do long tasks, and how that task duration has been doubling? That study is also based on test cases and not real-world implementation… so TBD on how “complete” those tasks actually are IRL.
This is where long context and memory come in.
The METR study proves that AI fails when it can't see the whole picture. Features like a 1 million token window allow an AI to read the entire codebase at once to understand its structure and standards. Memory helps it recall prior instructions and project goals (and hopefully, these capabilities get EVEN better). This is the type of thing that can solve the “middle-to-middle” problem of AI (the fact that we're often sucked into verifying, a.k.a. fixing, AI outputs instead of having it fully complete tasks all the way).
In this case, better memory and longer context windows could be exactly what's needed to bridge the gap between AI that passes tests and AI that writes actually usable code.
Think about it: when METR's agents failed to produce mergeable code, they weren't failing because they couldn't solve the core algorithmic problem, they were failing because they lacked the broader context about what makes code production-ready in that specific repository. They missed documentation standards, testing conventions, code quality expectations, and formatting requirements that any experienced developer working on that project would know from memory.
Current AI tools operate with a narrow window of immediate context, focusing solely on the functional requirements while ignoring the dozens of implicit standards and practices that make code actually mergeable. With better memory systems that can recall project-specific coding standards, past feedback on code quality, and the accumulated knowledge of what "good" looks like in a given codebase, AI could start addressing those 26 minutes of fixing that currently make even "successful" AI code submissions unusable… and potentially close the gap between feeling productive and actually being productive. From vibe-coding… to coding.