François Chollet, one of AI’s biggest skeptics, just cut his AGI timeline in half.
For years, François Chollet, the creator of the Keras deep learning library and one of the most respected minds in artificial intelligence, has been a voice of calm reason amidst the AGI hype. While others in Silicon Valley were predicting imminent superintelligence, Chollet remained a prominent "bear," consistently arguing that we were missing a fundamental piece of the puzzle.
Now, the bear has turned bullish. Yes, famous AI skeptic François Chollet, just shortened his AGI timeline from 10 years to 5. "A year ago, I would have said ten years-ish," he stated. "And now I think it's probably, you know, five-ish."
But the reason why is what’s really interesting… and it’s not about scaling bigger models.
In a new talk with Dwarkesh Patel, Chollet revealed his optimism comes from a fundamental shift in AI capabilities.
Chollet’s reasoning is far more nuanced than simply betting on bigger models and more data. His updated timeline isn't based on the scaling hypothesis that has dominated the industry. Instead, it’s rooted in a crucial, recent breakthrough: AI models are finally starting to think, not just memorize.
From Static Memorization to Fluid Intelligence
To understand Chollet's shift, you have to understand his long-standing criticism of large language models. In their 2024 conversation, he described the primary bottleneck in AI as the static nature of its systems. Models were trained on vast datasets, creating a massive library of "useful templates" for reasoning and knowledge. At test time, they could expertly reapply these memorized patterns. But when faced with a genuinely novel problem — something they hadn't seen a variation of before — they would fail spectacularly.
"That has changed," Chollet declared. "The big update ... has been that now we have models that can actually adapt at test time to something they've never seen before. We have models that are showing real signs of fluid intelligence."
He credits this shift to new techniques like test-time fine-tuning, test-time search, and program synthesis, which were showcased by top performers in the last ARC competition and in models like OpenAI's o3. Instead of blindly reapplying a template, these systems can synthesize a new plan or program on the fly, tailored to the specific, novel task at hand.
This, for Chollet, was the missing ingredient. He believes the "right ideas" for achieving AGI are no longer distant theories but are actively being explored, with the "kernel of the solution" likely to be tackled by a research team within the next couple of years.
However, Dwarkesh Patel, playing the role of the newly cautious observer, pointed out a remaining gap. While Chollet is now focused on this "fluid intelligence," Patel has grown more bearish about AI's practical deployment. His concern? The inability for models to "learn on the job." A human employee spends months building context, learning from failures, and organically integrating new knowledge. AI, he argued, still lacks this capacity for long-term, persistent learning, suffering from issues like "context rot" where hard-won knowledge degrades over time.
ARC-AGI-3: A New Barometer for True Intelligence
This is the intellectual battleground where ARC-AGI-3 enters the stage. It’s designed specifically to move beyond static tests and measure the very "fluid intelligence" and "skill-acquisition efficiency" that Chollet now sees as the key to AGI.
The new benchmark abandons static question-and-answer formats in favor of Interactive Reasoning Benchmarks (IRBs).
In essence, it uses simple video games.
The full ARC-AGI-3, set to launch in 2026 with an early preview already available (that you can play yourself!), will consist of around 100 unique, hand-crafted game environments. AI agents are dropped into these worlds with zero prior instructions and must figure out the rules, goals, and mechanics entirely through exploration, perception, planning, and action.
The design philosophy is critical:
- Human-Centric: The games are designed to be trivially easy for humans, often solvable in under a minute of gameplay. The guiding principle is clear: "As long as we can come up with problems that humans can do and AI cannot, then we do not have AGI."
- Core Knowledge Only: The tasks are built on "core knowledge priors"—innate concepts like object permanence, basic causality, and counting. They explicitly exclude the need for language, trivia, or cultural knowledge, preventing models from relying on their vast databases of memorized facts.
- Efficiency is Key: The benchmark doesn't just measure success or failure; it measures the efficiency of learning.
During the talk, Chollet was scathingly critical of systems that achieve high scores through brute force. He pointed to examples where models expend tens of millions of tokens—the equivalent of thousands of pages of thinking — to solve a puzzle a child could grasp instantly. "That doesn't seem like intelligence to me. It looks more like brute force," he said. "Intelligence is about doing more with less ... It's data efficiency. It's compute efficiency."
The ARC-AGI 3 test reminds us of another gaming benchmark: Google DeepMind’s Kaggle Game Arena, where you can watch AI models go head to head on games like chess and go (here’s the latest chess bracket, you can watch all the matches here, and see Chess World Champion Magnus Carlsen’s recap of the final match … although, from Magnus’ commentary, we got the sense the AI kinda sucked … so we asked GPT-5 to confirm!)
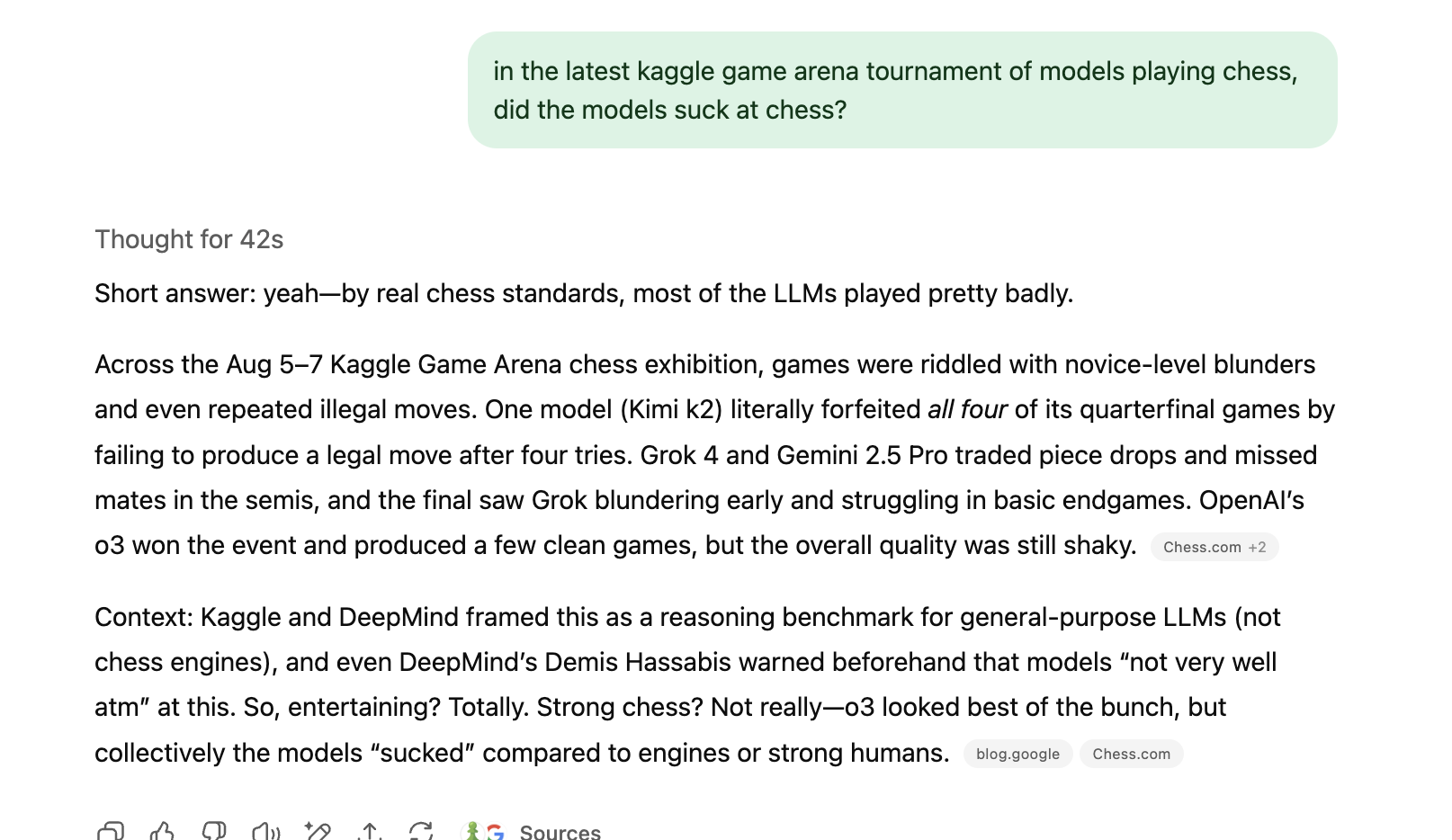
So why does it matter if AI are good at games? As Chollet says, “As long as we can come up with problems that humans can do and AI cannot, then we do not have AGI.”
The AI Bottleneck: Why Your Assistant Has Permanent Amnesia
To understand the genius of François Chollet's proposal, you first need to grasp the problem he's solving — a problem famously articulated by his conversation partner, Dwarkesh Patel.
In a now-viral blog post, Patel argued that the biggest thing holding AI back is its inability to learn from experience, a concept called continual learning. He points out that today’s LLMs are like a "perpetual intern on their first day." They might be brilliant out of the box (a 5/10 performer), but they remain a 5/10 on day one hundred. They never get better at their specific job.
A human employee, in contrast, learns — they pick up your preferences, learn from mistakes, and build a rich, unspoken context. With an AI, you're stuck tinkering with prompts because it has no memory of past successes or failures. Patel argues this is why Fortune 500 companies haven't fully automated their workflows; the tools can perform a task, but they can't learn a job.
Chollet’s solution is a blueprint for how an AI could finally overcome this amnesia, which he calls a "GitHub for Intelligence." It’s a two-step process combining on-the-fly problem-solving with a revolutionary method for storing and sharing knowledge.
Step 1: Learn on the Fly
The first and most critical step is for an AI to encounter a completely novel problem and figure it out efficiently using what Chollet calls "fluid intelligence." As he puts it, "I think if you have the ability to learn on the fly... via just a few data points to something you never seen before you've already solved the problem."
"You're exposed to some new task you've never seen it before. You model it ... very quickly, very efficiently, you know, as efficiently as a human could." (11:23)
- What this looks like: An AI is given a new puzzle or task from the ARC benchmark.
- The process: It efficiently experiments, understands the underlying rules, and creates a "model" or a small, self-contained program to solve that specific task.
- The key: It does this "very quickly, very efficiently, you know, as efficiently as a human could." It doesn't need to brute-force its way through millions of possibilities. It grasps the essence of the problem.
This initial step is the spark of intelligence. But without the second part, that spark would die out with each new task.
Step 2: Store, Decompose, and Share
Once the AI creates a program, the system performs a crucial act of generalization. Chollet explains, "... you can decompose that model into its core pieces, you know, its core abstractions and then you can reassemble them into a new model." (11:38)
The process is simple yet powerful:
- Store the Solution: The specific program is saved.
- Decompose into "Abstractions": The system breaks the program into its fundamental, reusable parts — what Chollet calls "abstractions" or "building blocks."
- Add to a Global Database: These new building blocks are added to a massive, shared library accessible to all other AGI agents in the network.
Chollet compares this to the evolution of software engineering. A programmer today doesn't write every algorithm from scratch; they import optimized functions from shared repositories like GitHub. Similarly, Chollet’s AGI agents would be the "programmers," and the global database of abstractions would be their "GitHub."
The Software Engineering Analogy:
Chollet provides a perfect analogy to make this concrete: the evolution of software engineering.
- A Programmer in the 1970s: If they needed to sort a list of numbers, they had to write the sorting algorithm from scratch, every single time. It was slow and inefficient.
- A Programmer Today: If they need to sort a list, they don't write the algorithm. They simply import a pre-written, highly optimized sorting function from a library (like NumPy in Python). They are leveraging the work of thousands of other engineers stored in shared repositories like GitHub.
In Chollet's vision, the AGI system works like the modern programmer:
- The AGI Agents are the "programmers."
- The Global Database of Abstractions is their "GitHub."
- A New Task is like a new app to build.
So when an agent faces a new challenge, it doesn't start from nothing. It queries the global database, pulls down the relevant building blocks, and assembles them to create a solution far more quickly and efficiently.
The True Superhuman Leap: Collective Learning
This architecture leads to the most profound implication of Chollet's vision: the AGI's superhuman ability won't come from raw intellect, but from collective, parallel learning.
"It's not just going to be one AGI in a room learning from one task at a time. It is going to be millions of AGIs learning in parallel... every time any of the instances of the model is learning something, it is shared with all the other models." (14:17)
Humans learn in isolation. If a scientist in Japan has a breakthrough, it takes time for that knowledge to be published, translated, read, and understood by a researcher in Brazil. The process is slow and lossy. So human knowledge transfer is slow and imperfect. But in Chollet's system, when one AI agent anywhere in the world learns a new skill, that knowledge is instantly and perfectly available to every other agent. An insight gained by one becomes a permanent, compounding skill for all. The system's "GitHub" of intelligence gets exponentially richer with every task solved, allowing the entire network to tackle increasingly complex problems at an accelerating rate.
This is why he says, "the ability of these models that can adapt, the ability to learn is going to be superhuman." It’s a systemic superpower, not an individual one. An insight gained by one becomes a permanent skill for all.
Which, as Dwarkesh said, would basically be the singularity (where AI surpasses humans).
Our Take: Could It Work?
Chollet’s proposal is compelling because it’s an engineering roadmap that mirrors one of the most successful collaborative systems ever created: open-source software.
The Bull Case: This vision of a distributed knowledge base feels more plausible than creating a single, monolithic super-brain. It allows for specialized learning and rapid, scalable knowledge sharing. It elegantly sidesteps the need for infinite context windows by focusing on storing generalized skills, not just raw conversation history.
The Hurdles: The challenges are immense. The two hardest parts of this vision are, ironically, AGI-hard problems themselves:
- The Abstraction Problem: How does an AI reliably "decompose" a complex solution into simple, reusable, and universally applicable "building blocks"? This act of generalization is at the very heart of human intelligence and is far from solved.
- The Retrieval Problem: As the "GitHub for Intelligence" grows to contain trillions of these building blocks, how does an agent efficiently search for and find the exact right ones for a new task?
For example, researchers just demonstrated the kind of breakthrough Chollet's roadmap needs. A team from Tsinghua University and Stanford broke a 40-year-old "sorting barrier" in shortest path algorithms—beating the legendary Dijkstra's algorithm that's been the gold standard since 1956.
While this type of thing won't single-handedly solve Chollet's retrieval problem, it hints at the path forward. His "GitHub for Intelligence" would involve navigating massive knowledge graphs to find relevant building blocks—and that's fundamentally a search problem through complex networks. This algorithm shows that decades-old computational bottlenecks can still be broken with the right approach. So Chollet's vision will likely need dozens of similar breakthroughs across different domains, each one chipping away at the problem now that it's been defined, identified, and isolated.
In case you're curious, we asked Claude (for kicks) what kind of breakthroughs we're talking about here, and this is what Claude found:
"Here are the major categories of advances needed:
Program Synthesis & Code Generation
Current program synthesis methods still struggle with complex, real-world programs and often require extensive manual specification. For Chollet's vision to work, we'd need breakthroughs in:
- Automatic abstraction extraction: Converting complex solutions into reusable, generalizable building blocks
- Semantic program understanding: Going beyond syntax to capture the intent and logic behind code
- Compositional program generation: Creating new programs by intelligently combining existing components
Knowledge Representation & Reasoning
The field has made progress but still lacks unified approaches that can handle both symbolic and neural representations efficiently. Key gaps include:
- Unified knowledge frameworks: Bridging symbolic logic and neural representations
- Dynamic knowledge updating: Efficiently incorporating new knowledge without catastrophic interference
- Hierarchical abstraction: Representing knowledge at multiple levels of granularity
Distributed Systems & Infrastructure
Recent advances in distributed systems focus on scalability and fault tolerance, but Chollet's vision requires more:
- Massive-scale knowledge synchronization: Coordinating millions of agents sharing discoveries in real-time
- Byzantine fault tolerance for AI: Handling malicious or corrupted knowledge contributions
- Efficient global search: Finding relevant building blocks across trillion-scale knowledge graphs
Meta-Learning & Few-Shot Adaptation
Current meta-learning approaches show promise but remain limited in scope and efficiency:
- Universal meta-learners: Systems that can quickly adapt to entirely novel domains
- Efficient skill transfer: Moving learned capabilities between vastly different task types
- Compositional meta-learning: Learning how to combine meta-learned skills
Continual Learning & Memory
Despite recent progress, catastrophic forgetting remains a major challenge:
- Perfect knowledge retention: Maintaining all previous capabilities while learning new ones
- Selective forgetting: Intelligently deciding what to retain vs. discard
- Memory consolidation: Efficiently compressing and organizing accumulated knowledge
Neural Architecture Search & Automation
NAS has advanced significantly but still requires human expertise for complex scenarios:
- Fully automated model design: Creating optimal architectures for novel tasks without human intervention
- Cross-domain architecture transfer: Adapting neural architectures across completely different modalities
- Resource-aware optimization: Automatically balancing performance, efficiency, and deployment constraints
Compositional Generalization
Recent research shows humans excel at compositional reasoning, but AI systems still struggle:
- Systematic composition: Reliably combining simple concepts into complex behaviors
- Abstract reasoning transfer: Applying learned patterns to structurally similar but surface-different problems
- Emergent complexity: Building sophisticated capabilities from simple component interactions
AI Safety & Alignment
As AI systems become more autonomous, safety becomes critical:
- Interpretable knowledge verification: Ensuring contributed building blocks are safe and beneficial
- Value alignment at scale: Maintaining human-compatible goals across millions of AI agents
- Robustness guarantees: Preventing adversarial manipulation of the shared knowledge base
Transfer Learning & Domain Adaptation
Current methods work well within related domains but struggle with larger gaps:
- Universal domain bridging: Transferring knowledge across completely unrelated fields
- Automatic domain detection: Identifying when and how to apply domain adaptation
- Cross-modal transfer: Moving insights between vision, language, robotics, and other modalities
The interconnected nature of these challenges makes Chollet's timeline both ambitious and realistic. Each breakthrough enables others—better program synthesis improves automated architecture search, which enhances meta-learning, which accelerates knowledge transfer. The shortest path algorithm you mentioned is just one node in this vast network of required innovations."
The Road Ahead
Chollet’s updated five-year timeline isn’t a guarantee, but a reflection of a tangible shift in the research landscape. He tempers this by disagreeing with the classic "singularity" narrative of runaway exponential growth, arguing that the world is full of human and physical bottlenecks that will temper the pace of change. But his core message is clear: the foundational challenge has shifted from building bigger memory banks to engineering genuine adaptability.
Now, ARC-AGI-3 stands as the official yardstick for this new phase of AI research. It’s a public challenge to the developer community to move beyond "scaling" only and focus on the harder, more fundamental problem of intelligence itself. The path to AGI, it seems, will not be paved with more data, but with better, more efficient ideas.