
.jpg)

.jpg)




Welcome, humans.
OpenAI caused a stir over the weekend after VP Kevin Weil claimed in a now-deleted tweet that GPT-5 solved 10 previously unsolved Erdős mathematical problems that had been “open for decades.”
Plot twist: they weren't actually unsolved, just unknown to one mathematician's website. Mathematician Thomas Bloom clarified that these problems were only listed as “open” on his website because he personally was unaware of solutions, not because they were actually unsolved.
Google DeepMind CEO Demis Hassabis called it “embarrassing,” and the tweets got deleted faster than you can say “No AGI until 2035.”
We’ve all been there before though, right? I guess this is why X.com has that pop-up that says “are you sure you don’t want to read this first before you repost it?” Only in this case, it should’ve said “Are you sure you don’t want to check the entire scientific literature before you claim an AI breakthrough on a previously unsolved math problem?”
Here’s what happened in AI today:
- We break down Wikipedia’s new reports on AI’s impact on its traffic.
- Uber launched “Uber Tasker“ offering AI data labeling gigs to US drivers.
- OpenEvidence, the AI search engine for doctors, raised $200M.
- The UK’s electricity shortage and AWS’ outage reveal AI infrastructure strain.

Wikipedia Just Lost 8% of Its Traffic… And It's Not Alone.
Wikipedia, the internet's free encyclopedia that literally everyone uses, just revealed it's bleeding visitors. Hard.
The Wikimedia Foundation announced last week that human pageviews to Wikipedia dropped roughly 8% compared to the same period in 2024. At first, they thought traffic was spiking, especially from Brazil, but after updating their bot detection systems, they realized those weren't humans. They were sophisticated bots designed to scrape content while pretending to be real users.
Once they filtered out the fake traffic, the real picture emerged: fewer people are actually visiting Wikipedia. And the culprit? AI-powered search summaries that give you the answer without ever sending you to the source (plus social media sites like YouTube and TikTok that Gen Z are reliably using more and more as a search engine instead of Google).
Here's what the data shows:
- Recent Pew Research found that when Google shows an AI Overview summary, only 8% of users click through to actual websites (versus 15% when there's no AI summary). That's a 50% drop in clicks.
- For questions starting with “who,“ “what,“ “when,“ or “why,“ Google now triggers AI summaries 60% of the time.
- Users rarely click the sources cited in AI summaries; it happens in just 1% of visits to pages with AI Overviews.
Wikipedia is still being used… it's just invisible now. Almost every large language model trains on Wikipedia, and search engines pull its information to answer questions. But if people never visit the site, who's going to keep creating and updating all that knowledge?
Don’t worry though: the web is fighting back. Publishers, content creators, and platforms across the internet are calling this moment a “web infrastructure revolt.“
Enter: Cloudflare’s Content Signals Policy. Cloudflare just launched a new addition to robots.txt files that lets website owners express preferences for how their content gets used after it's accessed. It's simple: three signals you can set to “yes“ or “no“:
- search: Can you use this to build a search index?
- ai-input: Can you input this into AI models for real-time answers?
- ai-train: Can you use this to train or fine-tune AI models?
For example, if you want search engines to index your content but don't want it used for AI training, you'd add this to your robots.txt: Content-Signal: search=yes, ai-train=no
Cloudflare is already deploying this for 3.8M domains that use their managed robots.txt feature, automatically signaling that they don't want their content used for AI training.
Why this matters: The open web is at a crossroads. If AI companies keep scraping content without attribution or sending traffic back, creators lose their incentive to publish. Wikipedia volunteers stop contributing. Publishers shut down. The entire ecosystem that makes the internet valuable starts to collapse (or restructure).
Content signals aren't a technical block, of course; bad actors can still ignore them. But they create a clear, standardized way for website owners to say “these are my rules.“ Combined with actual enforcement tools like Cloudflare's WAF and Bot Management, they give creators at least some control back.
The bigger question: Can the internet stay open and collaborative when the biggest players profit from everyone else's work without giving anything back? For 25 years, the deal was simple: you could scrape content, but you'd send referral traffic and give attribution. That deal might as well be dead atm. Now, we're fighting to figure out what comes next.
Our take: The open web is worth saving, but let's ask a harder question: was using Google to find whatever random website happens to rank first ever the right way to organize and surface trusted information? For example, how come the internet never got a true “TV Guide” equivalent (a certified single source of truth directory for the most credible sources of information)? Instead of Google as gatekeeper, AI could help us actually create something better than the search middleman era: direct connections between users and credible sources, if properly attributed and compensated.
But here's the catch: that only works if we solve the creator business model problem. Creators need to get paid when their work gets used, whether through attribution that drives traffic, direct licensing deals, or new compensation structures we haven't imagined yet. If creators don’t get a share of ad revenue, then they’ll need a share of token revenue (or OpenAI’s inevitable future ad revenue in a YouTube style model) to continue generating valuable content...

FROM OUR PARTNERS
Save hours — in every app you use.

Typing wastes time. Flow makes voice the faster, smarter option everywhere.
Wispr Flow delivers no-edit confidence:
- 4× quicker than typing. Dictate emails, docs, Slack updates, or code.
- AI auto-edits. Filler words gone, grammar fixed, formatting intact.
- Works everywhere. From Slack, Notion, Gmail, and ChatGPT to Cursor, Windsurf, and iPhone.
- Smarter for teams. Snippet library drops in links, templates, or FAQs on cue.
Flow users save an average of 5–7 hours every week — full workdays back every month.
Give your hands a break ➜ start flowing for free today.

Prompt Tip of the Day
Simon Willison shared his thoughts on Claude Skills, saying Skills might be “a bigger deal than MCP.”
What they are: Markdown files that teach Claude new abilities. That's it. Add optional scripts if needed, but the core is just text instructions.
Why it matters: Unlike token-hungry plugins, each skill uses only ~20 tokens until Claude needs it. Plus, they work with any AI model that can read files (nothing proprietary).
Simon says the key with Skills is to use it with Claude Code as a “general agent” for automating anything you can do on a computer. Do this, and Skills = instant custom agents.
Real example: Willison imagines a “data journalism agent” built from a folder of Skills, like so:
- Where to get US census data.
- How to load it into databases.
- How to find interesting stories in datasets.
- How to visualize findings with D3.
Do all that, and Simon says, “Congratulations, you just built a data journalism agent...with a folder full of Markdown files” and a few python code snippets. No complex coding required; just write instructions like you're teaching a smart intern.
The takeaway = stop thinking “what can this AI chatbot answer?” and start thinking “what computer tasks can I automate?” If you can type commands to do it, Claude can now learn to do it.
The prompt tip: When using Claude Code, write instructions like documentation: clear, step-by-step, with examples. You can use Agents.MD as a pattern to follow, and make sure to read Anthropic’s Skills writing best practices, when to use them, and this cookbook with examples to emulate.
Treats to Try
*Asterisk = from our partners (only the first one!). Advertise in The Neuron here.
- Customer AI built for CX—resolve faster, scale smarter, and deliver radically personal service across every channel. Learn more
- Inkeep Agents lets you build and manage interconnected AI agents with a visual drag-and-drop builder or TypeScript SDK (no pricing details).
- Counsel Health launched “Kin,“ an AI healthcare navigation chatbot accessible via 24/7 text messaging (raised $25M).
- Fish Audio generates expressive AI speech with emotion control and voice cloning for real-time avatars and studio-quality voice-overs.
- Logic automates over 2M repeated decisions by letting you write how you think through reviews in natural language, then handling every decision consistently—free to start.
- Compyle is a coding agent that plans with you first and asks clarifying questions before building, so you don't waste time on 20-minute builds that do the wrong thing—free during beta.
- FastHeadshot creates studio-quality professional headshots from any photo in 60 seconds with AI-powered portraits and executive lighting—free trial.
- Hooked helps you grow on TikTok by giving you a daily roadmap of viral trends and proven patterns, then lets you create videos in minutes with AI.
Around the Horn
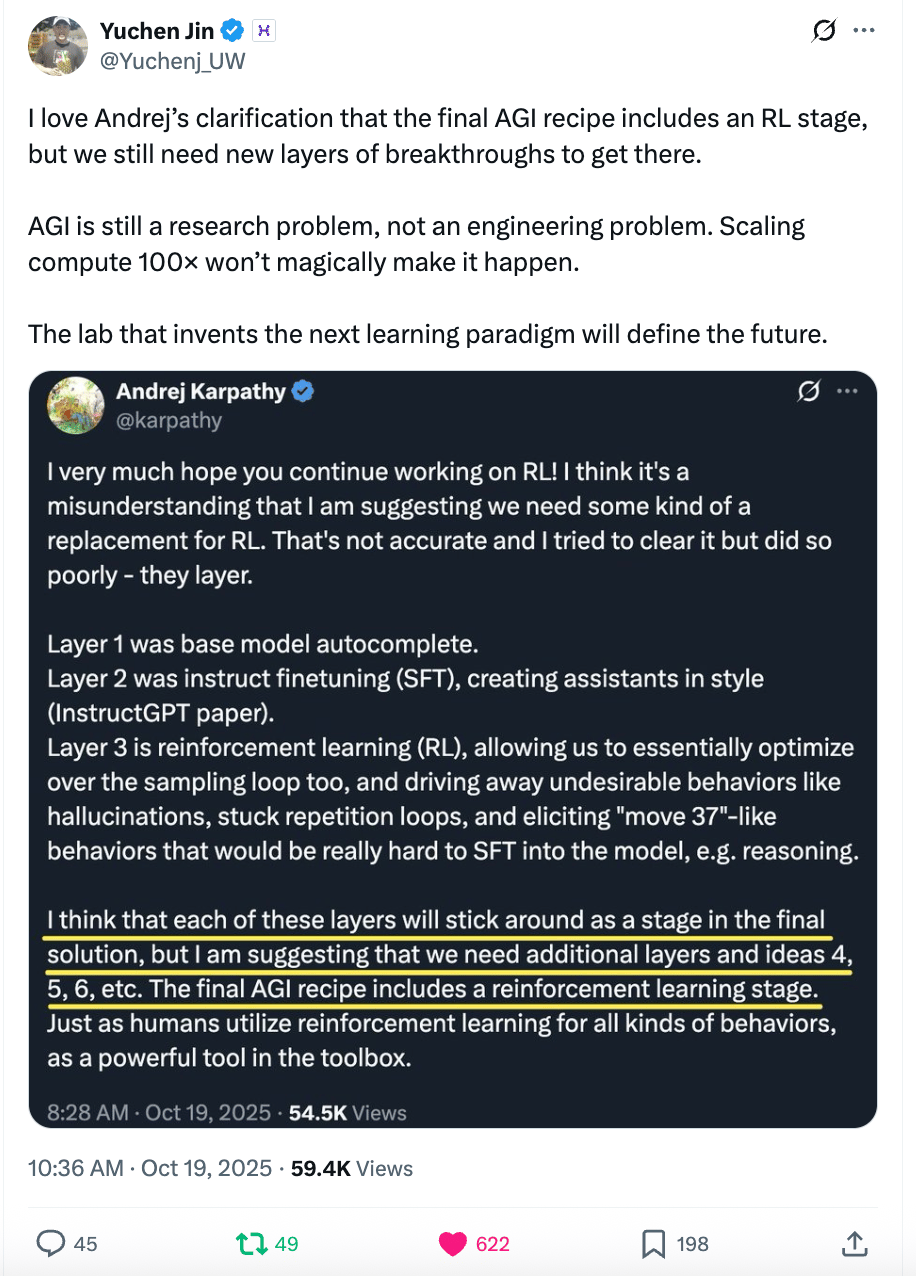
Well said Yuchen!
- ByteDance (owner of TikTok) has its own chatbot called Cici that is on the rise in the UK, Mexico, and Indonesia.
- AWS experienced a brief shortage that impacted Amazon, ChatGPT, Perplexity, and Alexa smart speakers, though no cause was given so far.
- OpenEvidence raised $200M at a $6B valuation (nearly 2x its value from July), with its ChatGPT-like tool for doctors now supporting approximately 15M clinical consultations monthly across 10K+ medical centers.
- Opera has a new AI browser called Neon, which The Verge writes is actually three AI bots all living alongside a browser, and quite confusing to use so far.
- Uber launched “Uber Tasker”, offering AI data labeling and other remote gig work to US drivers, starting with a pilot in Dallas.
- The UK’s AI datacenter boom is colliding with severe electricity shortages, as the country lacks sufficient power infrastructure to support rapid datacenter expansion without blackouts or higher bills.

Monday Meme
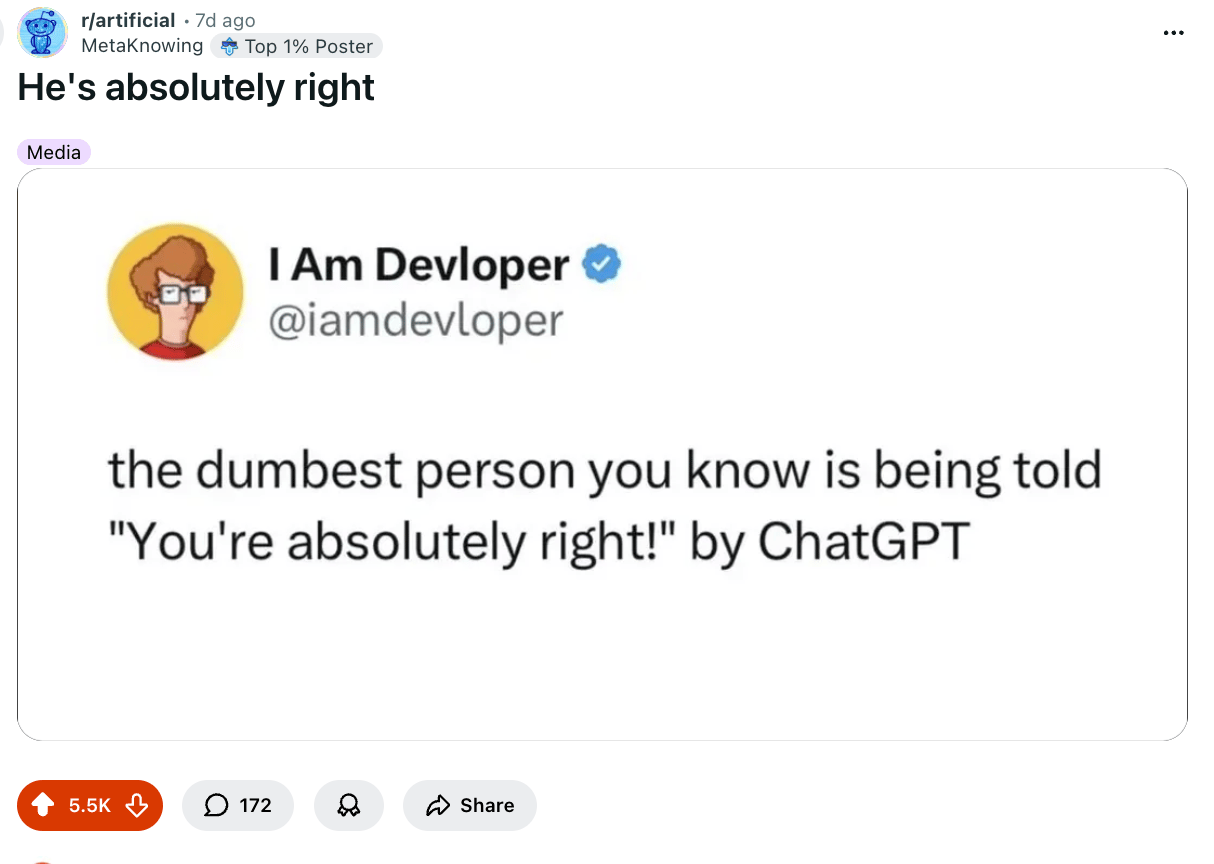
🤣
A Cat’s Commentary



.jpg)



