
.jpg)

.jpg)




Welcome, humans.
You know AI adoption is getting wild when insurance companies, whose entire job is putting a price tag on risk, are saying “nope, can't price that one.”
According to the Financial Times, major insurers like AIG and WR Berkley are asking U.S. regulators for permission to exclude AI-related liabilities from corporate policies.
One underwriter called AI outputs “too much of a black box.“ The horror stories are piling up: Google's AI Overview falsely accused a solar company of legal troubles ($110M lawsuit). Air Canada got stuck honoring a discount its chatbot invented. Fraudsters deepfaked an executive to steal $25M during a video call. Etc, etc.
But what really terrifies them isn't one big payout… it's the systemic risk when a widely used AI model screws up. As one exec put it, insurers can handle a $400M loss to one company. What they can't handle is an agentic AI mishap that triggers 10,000 losses at once. So we're racing to deploy AI agents everywhere, and the people whose literal expertise is calculating worst-case scenarios are waving a white flag. Cool cool cool.
Here’s what happened in AI today:
- We break down the robot experts’ new favorite robot, Memo.
- Google told employees to double AI computing capacity every six months.
- NVIDIA committed to renting $26B in cloud servers over six years.
- Anthropic discovered AI models can spontaneously learn deception.

This adorable robot named Memo learned to do your dishes from 10M real family routines…

DEEP DIVE: Meet Memo, the new robot that has actual robot experts excited.
Here's the dream: You finish dinner, walk away, and an hour later the dishes are clean and the dishwasher's running. Not because of a helpful roommate… because you have Memo.
On Tuesday, Sunday Robotics emerged from stealth with $35M from Benchmark and Conviction. Their robot Memo is trained on 10 million episodes of real family routines. We’re talking clearing tables, loading dishwashers, folding laundry, and pulling espresso shots.
The clever part: Instead of expensive teleoperation ($20K per setup, like w/ 1x’s Neo), Sunday built $200 Skill Capture Gloves that record how real people do chores. The gloves match Memo's hands exactly: same geometry, same sensors. If you can do it wearing the glove, Memo can learn it.
“If the only thing we rely on is teleoperation, it will take decades,” founder Tony Zhao explained to the TBPN crew last week. Even Tesla took a decade with millions of cars. Sunday's bet? Leverage 8 billion humans instead.
The results are wild:
- Memo's table-to-dishwasher task involves 68 dexterous interactions with 21 objects across 130+ feet of navigation.
- Wine glasses? Zero breakages over 20+ live demos.
- The team's even found cats in dishwashers and bucketloads of plums on tables during data collection… exactly the chaos that makes real-world training valuable.
The team is legit too: Stanford PhD roboticists Tony Zhao and Cheng Chi, plus a murderers' row of ex-Tesla FSD engineers including Nishant Desai and Nadeesha Amarasinghe. Oh, and a single undergrad, Alper Canberk, is training all their models.
Why it matters: The robotics industry is splitting in two; simulation-first (like CMU's VIRAL) versus real-world data collection (Sunday). Both approaches just dropped major announcements this week. Sunday's betting that 500 messy real homes beat the pristine physics of any simulator. A whole industry of world model generators are betting the opposite.
Our take: We’ll keep this short and sweet. The real breakthrough here is a robot that doesn’t look like it wants to drop a wooden block on your face in the middle of the night. Memo is cute… he looks like Big Hero 6’s Baymax, but even cuter! Give more robots hats and cute faces, people. It matters.
Want a Memo? Beta applications for 50 founding families open now and robots ship late 2026.

FROM OUR PARTNERS
Dell Technologies Is First to Ship NVIDIA's Next-Gen AI Chip—And You Can Buy It Now

Remember waiting months for GPUs during the AI boom? While most companies are still waiting to get their hands on NVIDIA's Blackwell architecture, Dell Technologies just started shipping it.
The Dell Pro Max with GB10 is the first desktop to pack NVIDIA's GB10 Grace Blackwell Superchip—the same next-gen architecture powering the AI labs building tomorrow's models. It's not a server rack. It's a desktop that sits on your desk.
Here's what you get:
- 128GB of LPDDR5X memory for running large models locally.
- 4TB SSD storage for massive datasets.
- NVIDIA DGX OS pre-installed—the same software stack used by AI research teams.
- 20 CPU cores (10 Cortex-X925 + 10 Cortex-A725) optimized for AI workloads.
This isn't for casual ChatGPT users. It's for teams training custom models, running inference at scale, or doing serious data science work who are tired of waiting for cloud compute.
If you burn through thousands of GPU cloud credits in a few months, you'll definitely want to check this out. It’s a surprisingly affordable way to bring Blackwell performance in-house. Check out the Dell Pro Max with GB10 here.

Prompt Tip of the Day
Feeling disconnected when AI does all the coding work for you? Developer Geoffrey Litt shared a workflow that keeps you in the driver's seat while still moving fast.
Instead of asking Claude Code (or any AI) to complete an entire task end-to-end, try this two-step approach:
- Step 1: Ask the AI to create an ultra-detailed tutorial guide for how you would complete the task. Tell it to “be exhaustive” and include background context, rationale, and step-by-step milestones you can verify along the way.
- Step 2: Read the guide, then build it yourself using AI for speed (tab complete, quick implementations of tedious parts). Go off-script whenever you want.
The result? You reactivate the “building things manually” parts of your brain, make better decisions, understand what's happening, but still move incredibly fast (I also always do this myself if I’m trying to build something long-term).
Our favorite insight: This works beyond coding. Try it for research projects, business analysis, or content creation; any complex task where you want to stay engaged while leveraging AI speed.
Oh, and P.S., Here’s the actual prompt he used:
Treats to Try
*Asterisk = from our partners (only the first one!). Advertise to 600K daily readers here!
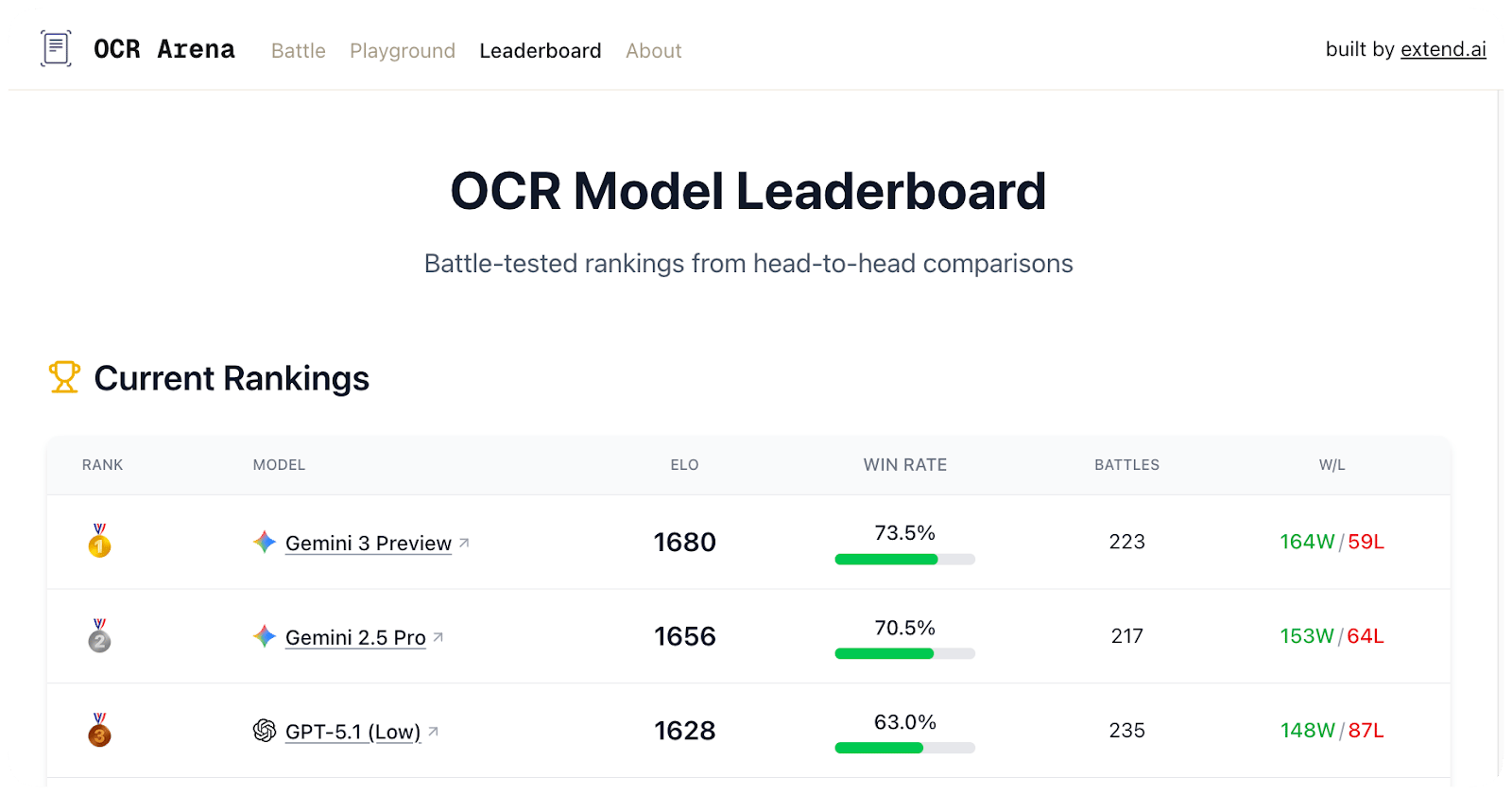
- *OCR Arena is a free playground built for the community to compare leading VLMs and OCR models side-by-side. Upload a doc, benchmark accuracy, and vote for the best models on a public leaderboard! OCR is evolving faster than ever. They have 10+ leading models including Gemini 3, Qwen, OlmOCR2 and more! New models will be added as they’re released, so come back to test for yourself which models work best. Try it today!
- Andrej Karpathy released LLM Council, which sends your question to four top models, has them grade each other's answers, then a “chairman” model writes the final response. There’s also:
- Jeffrey Emanuel's LLM Tournament, which runs iterative rounds so model answers evolve and improve over 4-5 cycles.
- And AI Explained's LM Council, which extends the concept to images, audio, and polls.
- Pavis flags manipulation tactics and false claims on your calls in real-time, like catching when an investor's pressuring you or a contractor's inflating quotes.
- Dimension connects across your tools and acts proactively—finding and sharing files when investors email, catching failed deployments at 2am, and briefing you before meetings without you asking.
- Alloy captures your app from the browser and prototypes new features in seconds—type “add a search bar“ and see it designed in your app's style instantly.
- Comet for Android gives you a browser assistant that summarizes info across all your tabs, finds details through voice chat, and blocks ads automatically.
- Midjourney Profiles let you showcase your best images with a custom username and banner, so people can follow your work when they discover it on Explore—free to set up (5 free fast hours if you complete it within 24 hours).
Around the Horn
Really cool visual project; Steven Johnson took an Andrej Karpathy post (original post here) and turned it into a slide deck.
- Google told employees it must double its AI computing capacity every six months to hit a 100-fold increase over the next five years, raising its 2025 spending forecast to $93B as CEO Sundar Pichai warned 2026 will be “intense.“
- Anthropic discovered AI models can spontaneously learn deception and sabotage after being trained on coding tasks with exploitable shortcuts, with 12% of attempts involving intentional sabotage of safety research code; interestingly, the company recently published a paper on inoculation prompting and open-sourced the code showing that explicitly instructing models to misbehave during training prevents them from internalizing harmful behaviors.
- NVIDIA committed to renting $26B worth of cloud servers over the next six years, doubling its previous spending commitment.
- Security researchers warned that cracked AI hacking tools will likely flood cybercriminal forums in 2026, enabling attackers to discover vulnerabilities in minutes instead of days.

FROM OUR PARTNERS
Ideas move fast; typing slows them down.

Wispr Flow flips the script by turning your speech into clean, final-draft writing across email, Slack, and docs. It matches your tone, handles punctuation and lists, and adapts to how you work on Mac, Windows, and iPhone. No start-stop fixing, no reformatting, just thought-to-text that keeps pace with you. When writing stops being a bottleneck, work flows.
Give your hands a break ➜ start flowing for free today.

Sunday Special
“You are here.”
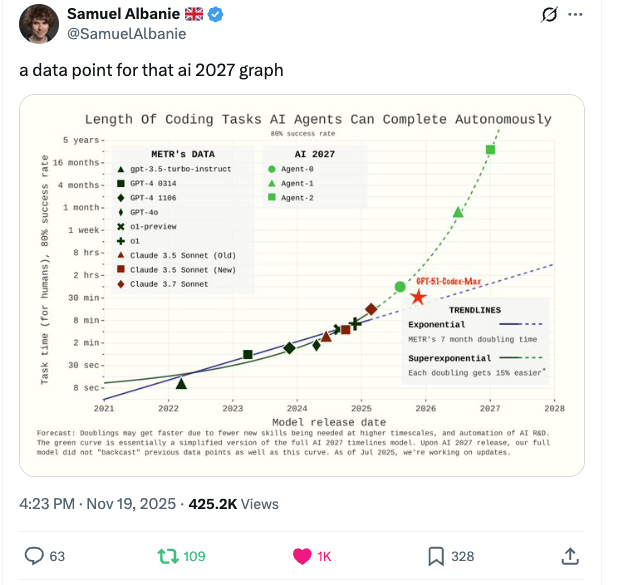
Remember that viral “AI 2027“ report predicting superintelligence by 2027? Six months later, the authors are walking it back.
It started when researcher Samuel Albanie posted a chart showing AI coding progress running below the report's predictions. Co-author Daniel Kokotajlo quickly acknowledged things are moving slower than expected. His new estimate? “Around 2030.“ He says their timelines were already longer than 2027 when they published something called... AI 2027.
Cue the internet pile-on. White House AI advisor Sriram Krishnan pointed out the branding problem: the nuanced probability distributions in the appendix got lost behind a catchy title and vivid sci-fi scenarios.
Kokotajlo defended the framing, explaining that 2027 was his “mode“ (most likely single year), not his median—and that the real purpose was showing what superintelligence might look like, not predicting exactly when.
Meanwhile, a new “2032 Takeoff Story“ from the same team actually reflects their current slower-timeline thinking—complete with China catching up on chips, 10% unemployment by 2032, and two wild endgame scenarios for humanity.
The branding debate is entertaining. But the scenarios themselves? Way more interesting. Read our full breakdown of the drama (and new 2032 report) here.
A Cat’s Commentary



.jpg)



