
.jpg)

.jpg)





Welcome, humans.
Not to start another blurb with more robot content, but we spent way too much time this weekend watching a 6-foot-1, 190-pound humanoid do a full 360-degree jump. The video was shared by the guy basically making the equivalent of robot UFC matches, and honestly, it's both impressive and slightly terrifying.

It looks animated, but shockingly, it is NOT.
There's also this wheel-legged T-REX robot who’s got hops of his own. When you see these demos, you start thinking: okay, the robot apocalypse is gonna be athletic.
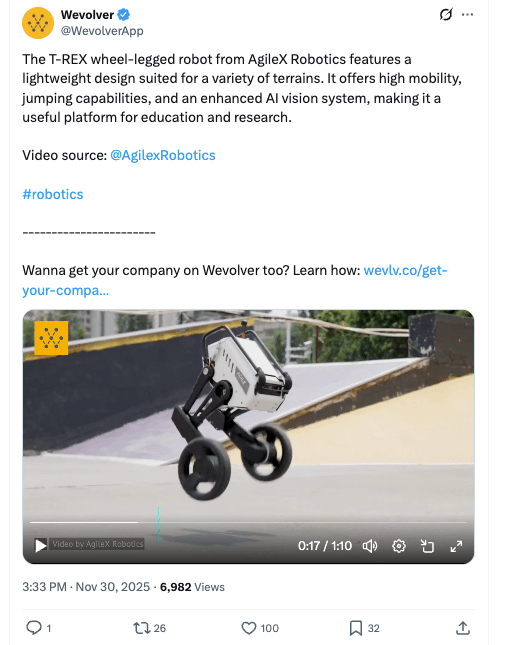
But then you look at what's actually deployed at scale in China, and it's... a wheeled humanoid scrubbing toilets in hotel bathrooms. The Zerith H1 is wiping down sinks, mopping floors, and restocking toilet paper at malls and public buildings. Not exactly the dystopian future we imagined, but probably the one we actually needed?
Oh, and there are robot traffic cops rolling around Hangzhou intersections directing cars. Which raises an important question nobody asked in the development meeting: will people actually listen to a robot cop, or is this just a prototype to get people used to robot cops before, y’know, robocop.
Side note: fans apparently remade all of Robocop. Here’s a sample scene. Pass it on.
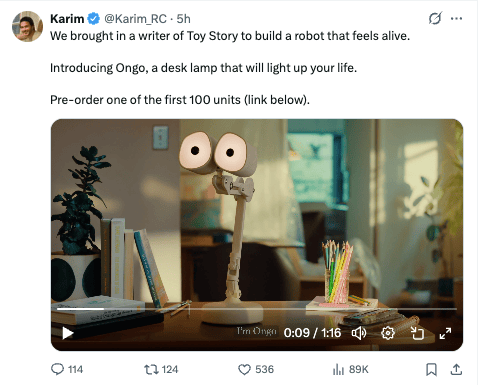
Lastly, I’ll leave y’all with this: Ongo, a desk lamp that’s half Pixar, and half Tim Burton, but totally 100% real…
Here’s what happened in AI today:
- DeepSeek launched two new models to push the frontier of AI research forward.
- GenAI video startups Runway and Kling launched new models.
- Amazon launched the Nova 2 Family and new Nova Forge.
- OpenAI and Anthropic published new research on AI safety and alignment.

Everything to Know About DeepSeek V3.2
DEEP DIVE: Read the full technical breakdown here
To the U.S. AI industry, the word “DeepSeek” might as well be synonymous with “Death Star.” It’s not that DeepSeek is a world destroying threat to the rebel alliance… it’s more like DeepSeek is a value destroying threat to their stock prices (at least, that’s how it went down last time DeepSeek launched something!).
Well, DeepSeek is back this week: it just dropped V3.2 and V3.2-Speciale—two models that make long-context AI actually affordable.
Here’s how it works: The breakthrough = “Sparse attention.” What is that? Allow us to explain…
- Think of it like a smart filter that lets the AI focus only on what matters, rather than re-reading everything constantly.
- Most AI models slow down massively as conversations get longer.
- With traditional attention (how ChatGPT works), a 100,000-word document costs 100× more to process than a 10,000-word one.
- With DeepSeek's approach, that same document costs closer to 10× more. That's a 10× efficiency gain.
And that’s not all… V3.2-Speciale is the first model to achieve gold medals across IMO 2025, CMO 2025, IOI 2025, and ICPC World Finals. As researcher Jimmy noted: “They released IMO gold medal model before Google or OpenAI.”
On AIME 2025, Speciale scores 96.0% versus GPT-5's 94.6% and Gemini-3.0 Pro's 95.0%. On HMMT February 2025, it hits 99.2%—the highest among reasoning models.
That performance comes with a trade-off, though: Speciale generates 23K-45K tokens (you can think of tokens as roughly equal to words) per complex problem, versus 13K-18K tokens for competitors. As Artificial Analysis explained to us last week, producing more tokens per answer adds up… depending on the cost of the tokens. But at $0.40 per million tokens for Speciale compared to GPT-5's $10 (25x cheaper) and Gemini's $12 (30x cheaper), you're still looking at 5-10x cost savings.
How they built it:
- DeepSeek threw serious compute at reinforcement learning; where the AI learns by trial and error.
- They ran 2,000 training steps across 1,800 simulated environments (coding challenges, math problems, database queries) with 85,000 complex instructions.
- They also used a clever two-stage approach: first training a lightweight “indexer” to learn which parts of conversations matter, then switching the whole model to sparse mode.
Why all this matters: DeepSeek published everything. Their full technical paper explains the sparse attention process, the RL training methodology, and even their failure cases. When DeepSeek figures out how to make long-context reasoning 10× cheaper, they share the blueprint so every lab can build on it. For now, anyway.
So as you can see, the competitive pressure from Chinese AI labs isn't slowing; it's accelerating. Western labs will probably follow DeepSeek's lead on its more attractive ideas (sparse attention and automated RL) within 6-12 months.
Access: V3.2 is available now via API. V3.2-Speciale runs on a temporary endpoint until December 15th while DeepSeek gathers feedback.

FROM OUR PARTNERS
Serious companies don’t run on consumer AI

Nobody on your team thinks they’re leaking IP. They’re just moving fast. And the fastest tool in the browser is ChatGPT. So in go roadmap notes, pricing logic, client decks, even bits of code.
Sooner or later, leadership realizes the company’s knowledge flow has quietly been running through the same tool people use for travel plans and restaurant picks.
Sana Agents is what you use when your data actually matters. AI that lives with your stack, keeps your IP inside your walls, and integrates with the systems you’ve already invested in, so your team never needs a workaround.
If you're building an AI-first company, don’t build it on tools built for everyone else.

Prompt Tip of the Day
Forget better prompts—you need better context. AI engineer Hesam just shared a free 23-page guide on context engineering that shows you how to build the information environment your AI operates in. Building agents is about way more than what you say to it.
Here's the idea: even the smartest models hallucinate and forget things because they're missing the right information at the right time. Context engineering is about architecting the world your AI lives in.
The guide breaks down five key areas…
- Agent architecture: How to build AI that actually makes good decisions.
- Retrieval & chunking: Getting your AI the right info without overwhelming it.
- Memory systems: Teaching AI to remember what matters.
- Tool integration: Connecting AI to real data and APIs.
…with incredible diagrams (seriously, people in Hesam’s comments can't stop talking about the visuals!!):

image above is by @helloiamleonie
Oh, and in case this feels over your head? This isn't just for engineers. Understanding how context works helps you diagnose why ChatGPT or Claude keeps dropping the ball… and fix it. Plus, who doesn’t love a picture book? Skim through and you’ll probably learn something!

Treats to Try
*Asterisk = from our partners (only the first one!). Advertise to 600K readers here!
- *Still doing manual tasks repetitively? Join this 2-Day LIVE AI Mastermind by Outskill, an intensive training on AI tools, automations, and agent building so you can learn to automate 50% of your work. They’re running their Holiday Season Giveaway and first 100 people get in for absolutely free (it usually costs $395 to attend 🫨). Register here for $0 (first 100 people only) 🎁
- Function Health runs 100+ lab tests for you twice a year (covering hormones, cancer markers, heart health, metabolic panels, and more) to catch early disease indicators and track how your body changes over time—$365/year (so $1/day).
- Kling O1 unifies video generation and editing in one model; create videos from text/images/clips, edit with commands like “remove crowd” or “make it rainy,” save characters to an Element Library and reuse them consistently across any scene (no redrawing), stack multiple edits in one go (add + remove + restyle), and generate connecting shots that match your video's context—they also launched a new user guide and user experience.
- OpenArt aggregates 50+ image models (DALL-E, Stable Diffusion, FLUX, etc.) in one platform—switch between models, train custom ones for your brand style, edit with inpainting/upscaling tools, and keep characters consistent across scenes
- This is a deeply cool project: Trinity Mini handles complex reasoning tasks and powers custom agents while giving you full ownership and control of the model weights (26B parameters, trained end-to-end in the US, Apache 2.0 license meaning you can use it commercially); try it via OpenRouter for free for a limited time, then $0.045/$0.15 per million tokens (input/output), or via the free tier with rate limits at chat.arcee.ai.
- There’s also Trinity Nano (6B/1B active) which is also available now, and very soon, Trinity Large (420B/13B active) which is currently training on 2048 B300 GPUs, set to launch January 2026; uniquely, they are using small models to train a big model… whoa dude.
Around the Horn

- Runway released Gen-4.5, which generates videos from text prompts where you control camera movements, scene timing, and multiple elements at once; objects move with realistic physics (weight and momentum) in styles from photorealistic to stylized animation, and the model has outcompeted Google’s Veo 3 on the Artificial Analysis leaderboard, giving it the title of “best video model in the world.” (Unlimited plan is $95/month w/ unlimited generations in slow queue, plus 2,250 credits/month for fast generations; each clip is 5-10 seconds).
- Amazon just launched a new Nova 2 family that includes Nova 2 Lite (fast, cheap reasoning for everyday tasks like chatbots), Nova 2 Pro (most intelligent for complex work like agentic coding), Nova 2 Sonic (real-time speech-to-speech conversations), Nova 2 Omni (processes any content type and generates both text and images), plus Nova Forge (lets you build custom model variants by mixing your proprietary data into Nova's training) and Nova Act (automates browser-based workflows like updating CRMs with 90% reliability).
- OpenAI and Anthropic published new research on AI safety; Anthropic published a piece on AI finding smart contract exploits, and OpenAI released a new Alignment research blog, with two new articles: on debugging misaligned completions, and a practical approach to verify code at scale.

FROM OUR PARTNERS

Running 70B models usually means choosing between $8,000 GPUs or cloud bills that never stop. The Dell Pro Max with GB10 gives you 128GB for serious AI work at your desk.
Run Llama 3.3 70B for inference, fine-tune models on proprietary data, or build RAG systems without cloud APIs. Most workstations can't even load these models into memory—the Dell Pro Max with GB10 handles them while fitting under your monitor and plugging into a standard outlet.

A Cat’s Commentary


*Before you tell us “ACTUALLY it wasn’t Gatorade, it was Kool-Aid, guess again! ACTUALLY, it was Flavor-Aid 😛 )





