

So back on September 12, 2025, The Neuron did a deep dive live stream into the world of text-to-speech (TTS) AI models. Using Hugging Face's TTS Arena V2, a platform that pits two models against each other in a head-to-head battle for vocal supremacy, we put a variety of AI voices through their paces (you can watch the full video below).
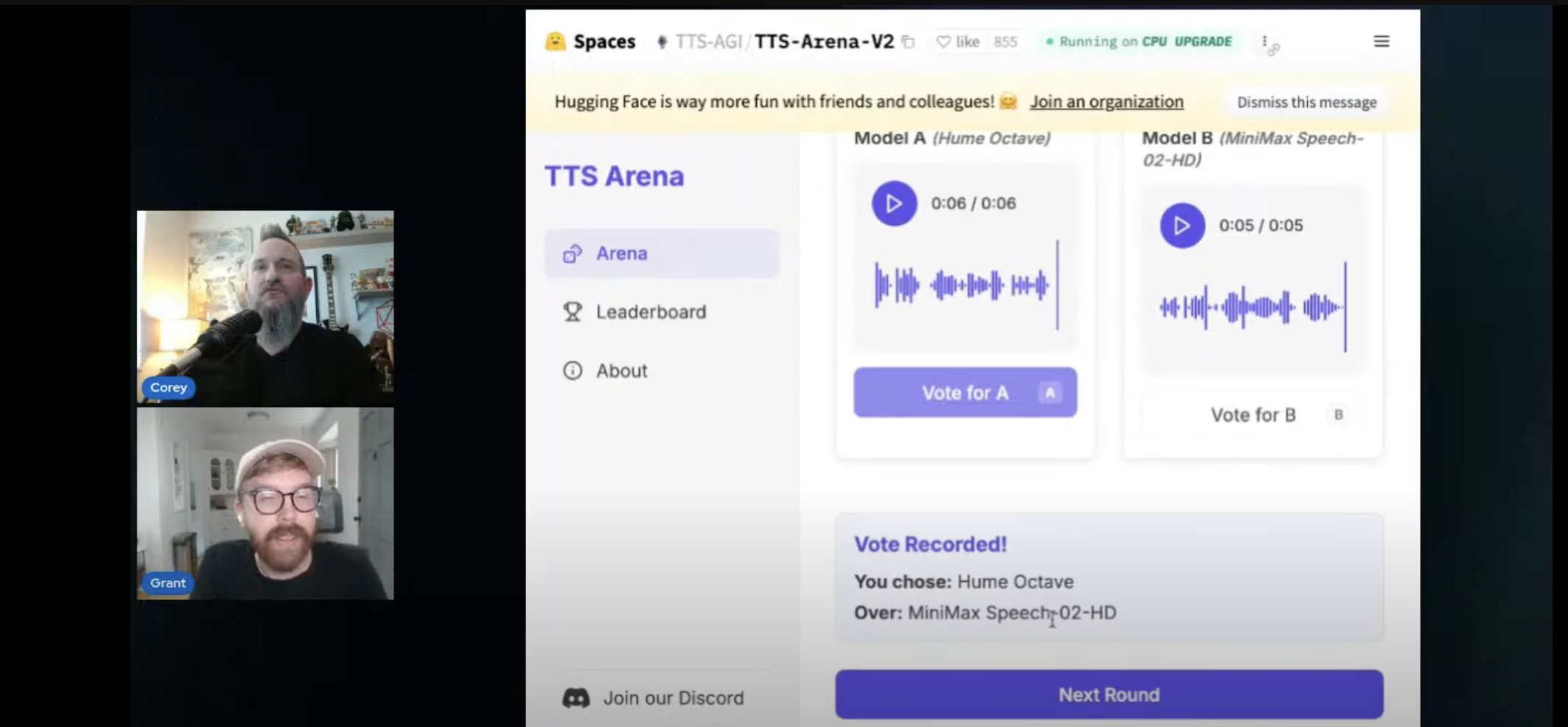
The arena's format is simple yet effective: a user inputs a piece of text, and two anonymous AI models generate their rendition. The user then listens to both and votes for the winner. To truly test the mettle of these models, we threw a diverse range of prompts at them, from quirky one-liners and dad jokes to poignant poetry, dramatic monologues, and tricky tongue twisters. Special shout out to the audience members who actively participated, casting their votes in the chat and contributing to our final "vibe bracket" (more on that below).
First up: What are TTS Models, Anyway?
TTS stands for Text-to-Speech—AI systems that convert written text into natural-sounding spoken language. This isn't your old GPS's robotic voice. Modern TTS uses deep learning, often with sequence-to-sequence models (s1,s2,...,sT) and attention mechanisms, to generate realistic prosody, rhythm, and intonation.
These neural TTS models are trained on thousands of hours of human speech paired with text transcripts, allowing them to capture emotion, accents, and style.
Here's How They Work
The process generally follows these steps:
- Text Processing: Input text is normalized. For example, $100 becomes "one hundred dollars" and abbreviations are expanded.
- Phoneme Conversion: Text is converted into its basic phonetic units (sounds).
- Acoustic Modeling: A neural network predicts acoustic features, like spectrograms, from the phonemes. A spectrogram is a visual representation of the spectrum of frequencies of a signal as it varies with time.
- Vocoder Step: A vocoder synthesizes the final audio waveform from the predicted spectrogram.
- Prosody Control: Many systems support SSML (Speech Synthesis Markup Language), allowing you to embed instructions like <break time="1s"/> for pauses or <emphasis level="strong"> to control delivery. Some advanced models can even adjust for whispering or singing styles based on natural language prompts.
The best moments from the episode
First up: if you want to watch the video itself, check out the timecodes below for the key moments.
- [1:02] Platform Insight: Hugging Face offers a "TTS Arena," a platform that functions like an LLM arena but for text-to-speech, allowing users to directly compare two models' outputs for the same text.
- [3:53] Point of View: Some early AI voice models have a distinct "newscaster" quality, which can make them sound simultaneously real and out of place for casual conversation.
- [5:23] Technical Insight: The hosts identify "artifacting" in AI audio, describing it as a subtle digital warble or an "autotune" quality on high frequencies, which detracts from the natural sound. A clear example of this is heard at (11:13).
- [7:26] Point of View: Judging an AI voice isn't just about clarity; it's about how fitting the tone and emotion are for the specific statement being read.
- [7:57] Industry Insight: 11Labs is positioned as the commercial benchmark in the text-to-speech space—the well-funded, high-quality "one to beat," though it can be more expensive than other options.
- [11:40] Technical Insight: Many models struggle to correctly interpret and apply pauses for punctuation like em dashes, a subtle but key element of natural human speech.
- [12:20] Point of View: Cocot-TTS is highlighted as one of the best smaller, open-source speech models available.
- [14:24] Insight: The most advanced models differentiate themselves by adding nuanced emotional emphasis, like sarcasm or passion, demonstrating a deeper understanding of the text's intent.
- [14:36] Actionable Takeaway: A poignant warning to "trust nothing you hear anymore" as AI-generated voices become indistinguishable from human ones.
- [20:34] Insight: As the technical quality of top-tier TTS models converges, personal preference for a specific voice's style and tone becomes the primary factor for users.
- [22:27] Point of View: The Castle Flow model is singled out as being exceptionally impressive and capable of producing dramatic, high-impact audio.
- [25:06] Technical Takeaway: You can visually gauge the quality of a voice model by its audio waveform; superior models show significant dynamic range (variance in peaks and lows), while robotic ones appear flat and compressed.
- [34:22] Technical Insight: The Hume Octave model is revealed to be a powerful "omni capable" hybrid system, combining technologies from OpenAI, 11Labs, and Google DeepMind to generate not just voices but entire personalities, accents, and emotional styles.
- [37:33] Industry Tangent: An observation on the AI industry's "vicious cycle": outsiders feel it's impossible to keep up, while insiders feel a constant, voracious demand for more tools, which only accelerates the pace of innovation.
- [47:36] Discovery: The hosts find that the Opa-v1-P1 model can correctly interpret an instruction given in an XML-style tag (<movie trailer style voice>) and apply the style without reading the tag aloud, showcasing a sophisticated level of contextual understanding.
- [50:14] Insight: The best models can pick up on implicit cultural cues within text—for example, recognizing the phrase "In a world..." as the start of a movie trailer and adopting the appropriate tone without being explicitly told.
- [1:22:05] General Direction: A key trend in AI is the rise of smaller, powerful, and highly specialized models (like Nvidia's Amplify) designed to run efficiently on edge devices, marking a shift away from massive, general-purpose models trained on the whole internet.
- [1:25:38] Industry Insight: The hosts discuss the central debate in AI development: whether to focus on training with smaller, perfectly curated datasets or to continue pushing the frontier with massive, broad datasets. The likely answer is that both approaches are necessary for progress.
- [1:31:55] Discovery: A demonstration of Microsoft's new live voice model attempting to sing produces an "unholy" and "terrifying" result with a strange "cathedral reverb," highlighting the often uncanny and bizarre outputs of cutting-edge generative audio.
- [1:44:39] AI News Insight: The hosts break down a major breakthrough from Thinking Machines (founded by ex-OpenAI CTO Mira Murati) that solves non-determinism in LLMs, an issue caused by "batch invariance."
- [1:46:01] Actionable Takeaway: The "batch invariance" problem means an LLM's response can vary based on server traffic. To get a better or different answer, you should try submitting the same prompt multiple times at different times of the day.
- [1:49:49] AI Research Tangent: A discussion of a recent OpenAI paper on hallucinations, which posits that models hallucinate because they are trained and incentivized to always provide an answer (to guess) rather than admitting they don't know.
- [1:53:54] Actionable Takeaway: The hosts demonstrate that developers and even "vibe coders" can use Google's AI Studio and the Gemini API to easily build their own podcast-generation tools from any source text.
Here's the "Vibe Bracket" Results
Here is the final tally of wins from our showdown:
- Inworld TTS Max: 5
- Papla: 4
- Kokoro (speed): 3
- Octave: 3
- Castleflow: 2
- MiniMax: 2
- Eleven Labs v2.5 Turbo: 1
- Eleven Flash v2.5: 1
- Chatterbox: 1
- WordCab: 1
- CSM 1B: 1 (in a head-to-head win over Dia 1.6B).
The Contenders and the Standouts
InWorld TTS Max emerged as the clear frontrunner in our bracket, consistently delivering realistic and context-aware speech that impressed across a wide range of prompts. Its ability to produce high-quality, natural-sounding audio earned it the top spot. Close behind was Papla, another standout performer that proved to be incredibly capable and versatile.
Hume Octave, described as a "next-generation speech model," was another top contender. It consistently impressed with its ability to capture nuance and emotion. Whether it was a sarcastic quip or a dramatic reading, Hume Octave delivered with a personality that felt strikingly human. Its capacity to take natural language instructions to alter its emotional delivery set it apart.
The more theatrically inclined Castleflow also had its moments in the spotlight. Its dramatic and often over-the-top delivery was likened to that of a movie trailer narrator, making it a fun and engaging choice that secured two wins. On the other end of the spectrum, WordCab TTS was generally found to be less impressive, though it did manage to win a round with a dad joke, its delivery amusingly compared to a TED talk.
The well-established Eleven Labs had a mixed showing. While a known powerhouse in the voice AI space, the hosts speculated that the versions available on the TTS Arena might be older iterations. Consequently, its performance was inconsistent. The smaller, open-source model Kokoro all had some impressive speed, reinforcing the growing importance of compact and efficient AI models. Minimax speech O2 also held its own, proving to be a high-quality and reliable option, but often a bit dry.
Key Takeaways from the AI Voice Throwdown
Several key themes emerged from this comprehensive exploration of the current state of text-to-speech technology. Perhaps the most significant was the sheer subjectivity of it all. As we repeatedly pointed out, what constitutes a "good" AI voice is often a matter of personal preference.
However, a clear differentiator for the top-performing models was their ability to grasp context and nuance. The models that could go beyond simply reading words and instead interpret the intended emotion, tone, and rhythm of the text were the ones that truly shone. Hume Octave was the undisputed champion in this regard.
The livestream also underscored the increasing sophistication and controllability of TTS models. The ability to provide natural language instructions for emotional delivery, as seen with Hume Octave, and the capacity for multi-speaker dialogue generation in Google AI Studio, point to a future where users have granular control over the synthetic voices they create.
Exploring the Broader Landscape of Voice AI
The livestream wasn't limited to the TTS Arena. We also took the opportunity to explore other cutting-edge voice and speech-related AI technologies. We checked out Nvidia's Parakeet, a 600-million parameter automatic speech recognition (ASR) model designed for high-quality transcription, complete with automatic punctuation and capitalization.
They also discussed Microsoft's VALL-E X, a remarkable neural codec language model capable of generating high-quality, personalized speech from just a brief audio sample. It low-key blew our minds with its ability to clone a voice from a short audio clip and even translate it into other languages while keeping the original speaker's tone.
We also explored some other cool voice AI tech. And we had a blast with the multi-speaker feature in Google's AI Studio, which let us generate a surprisingly coherent podcast from a script. While some of the results were a little on the "creepy AI" side, the potential for creating dynamic audio content is huge.
The Prompts
We tested the AI on a series of prompts, as mentioned above. We didn't use all of these ourselves, but if you want to replicate this and do a legit vibe benchmark, be our guests!
Conversational / Colloquial (Natural Speech)
- “Okay, but hear me out—pineapple on pizza isn’t a crime, it’s a lifestyle.”
- “Hey team, quick question: who finished the last pot of coffee? We need answers.”
- “If you’ve ever argued with a toddler about bedtime, you already know what negotiation at its toughest feels like.”
🎭 Dramatic Readings (Tone & Emphasis)
- “Once upon a midnight dreary, I tried to debug, weak and weary.”
- “Behold! The inbox has grown—three hundred unread messages, marching like an army.”
- “In a world of endless spreadsheets, one manager dared to color-code everything.”
😂 Light Jokes & Humor (Comic Timing)
- “Why did the marketer get kicked out of the meeting? Too many buzzwords per minute.”
- “My to-do list is like laundry. No matter how much I finish, there’s always more piling up.”
🔄 Contrast & Emotion Tests
- Excited: “We did it! The campaign hit one million impressions in a single day!”
- Deadpan: “Yes. Of course. Another four-hour budget meeting is exactly what I needed to feel alive.”
- Whisper: “Don’t tell anyone… but the printer has been working perfectly all week.”
🤹 Tongue Twisters with a Twist
- “She sells seashells by the seashore. The shells she sells are surely seashells.”
- “Brisk business bloggers balance buzzwords briskly.”
- “Smart software swiftly shifts, shaping strategies seamlessly.”
Our main takeaway:
The world of AI voices is exploding with options, and it's clear that context and emotional intelligence are the new frontiers. For creators and developers, this means it's time to experiment beyond the big names.
- For Nuance & Expression: Inworld TTS Max, Papla, and Hume Octave are must-tries for anyone needing expressive voiceovers.
- For Interactive Experiences: The multi-speaker capabilities of Google's AI Studio are a game-changer (you can literally use it to make your own podcast tool like NotebookLM!).
- Keep an Eye On: Smaller, open-source models like Kokoro are proving to be impressively nimble and high-quality.
The key takeaway? The "best" AI voice is highly subjective and depends entirely on your use case, but the quality and variety available today are nothing short of astounding.





