


There's a fundamental debate raging under the surface of the AI industry, one that questions the very foundation of today's generative revolution. On one side stands the colossal success of Large Language Models (LLMs), hailed as a monumental leap. On the other, a quieter but deeply influential school of thought, championed by Turing Award winner Richard Sutton, who argues this entire approach is a "dead end"—a sophisticated form of mimicry that will never lead to true intelligence.
Richard Sutton is the father of reinforcement learning, winner of the 2024 Turing Award, and author of The Bitter Lesson, an essay that argues no matter what humans do to design AI systems, simply scaling compute and using reinforcement learning will always outperform us. This essay has inspired the entire industry to become "scale-pilled", which means a belief that "scale is all you need" and if we just scale compute, we'll solve all of AI's tricky problems better than designing any sort of neurosymbolic system ourselves. And he thinks the entire Large Language Model approach that powers tools like ChatGPT is fundamentally flawed and won't lead to true intelligence (he also thinks our current deep learning methods are flawed, as his recent paper in Nature showed).
In a new interview with Dwarkesh Patel, Sutton argues that models like ChatGPT have a fundamental flaw: they learn to predict what humans would say, not what actually happens in the world. It's the difference between reading every cookbook ever written versus actually learning to cook by burning a few soufflés (or even tougher: surviving the first week of bake off).
As interviewer Dwarkesh Patel frames it, Sutton’s position is that "LLMs aren’t capable of learning on-the-job, so no matter how much we scale, we’ll need some new architecture to enable continual learning." Read the full transcript here.
This isn't just an academic squabble. The outcome will determine where trillions of investment dollars flow and whether we build systems that truly understand our world or merely reflect our own words back at us.
Below, we'll briefly summarize Richard's stance, and then we'll dive into the best moments from the episode, and dive into the larger debate in general below that.
- Richard's Points in Brief:
- Here are the top moments from the debate if you want to skim through it yourself
- Mimicking Intelligence Isn't Achieving It
- Sutton’s Alternative: The Architecture of an Experiential Agent
- The Unsolved Problem: Generalization
- A Concrete Architecture for a Post-LLM World
- The LLM Proponent's Counterargument: A Foundation for Intelligence, Not a Dead End
- Our Take
- UPDATE: Karpathy's Take: "We're Not Building Animals. We're Summoning Ghosts."
- The Bitter Lesson and the Inevitability of Succession
Richard's Points in Brief:
Richard's argument: LLMs, like ChatGPT, are masters of imitation, not understanding. They are trained to predict the next word, making them excellent at mimicking human text. But this means they can only model what people say about the world, not what actually happens in it. They lack the key ingredient for true learning: direct experience.
Here’s the architecture he believes we need instead:
- A Four-Part Agent: The agent needs a Policy (to decide actions), a Value Function (to predict long-term outcomes), Perception (to understand its current state), and a Transition Model (to predict the consequences of its actions).
- Continual Learning: Forget massive, static training runs. This agent would learn on-the-fly from a constant stream of sensation, action, and reward, just like an animal. New knowledge is integrated directly into the network’s weights, not crammed into a context window.
- Real Goals: Intelligence requires goals. Instead of just predicting text, this agent would be driven to maximize a reward signal, giving it a "ground truth" for what is a better or worse action.
Why this is the real path forward: Sutton argues that current AI, including LLMs, is terrible at generalization—transferring knowledge from one state to another without a human researcher carefully engineering it. An agent that learns from direct consequences, like the RL-powered TD-Gammon (Tesauro, 1994–1995) did back in the 90s, builds a more robust and flexible intelligence.
Sutton believes the industry is stuck in a paradigm of "training" and "deployment." His vision renders that obsolete. The next breakthrough won't come from a bigger GPT-5, but from an agent that learns about the world the same way we do: by living in it.
Here are the top moments from the debate if you want to skim through it yourself
On LLMs vs. Reinforcement Learning (RL)
- (1:46) Reinforcement learning is basic AI, focused on an agent understanding and figuring out its world. In contrast, Large Language Models (LLMs) are about mimicking people and what they say, not about an agent figuring out what to do for itself.
- (2:21) LLMs do not have real world models. Sutton disagrees with the premise that LLMs build robust models of the world. He argues that mimicking people who have world models is not the same as having a world model yourself. A true world model predicts what will happen in the world, whereas an LLM predicts what a person would say will happen.
- (4:00) The concept of a "prior" doesn't apply to LLMs because they lack a "ground truth." For knowledge to be a "prior," it must be an initial belief about a truth you can later verify. Since LLMs have no goal or objective measure of what is right or wrong in the world, there is no ground truth to have a prior about.
- (6:09) LLMs are not "surprised" by the world and don't learn from unexpected outcomes. An agent with a real world model makes a prediction, observes the outcome, and updates its model if surprised. LLMs don't have this mechanism for real-world interaction; they don't change based on what a user says in response to them.
- (7:48) Intelligence is the ability to achieve goals, and LLMs don't have substantive goals. Sutton defines intelligence as the computational part of achieving goals in the world. He argues that "next token prediction" is not a real-world goal because it doesn't seek to influence or change the external world.
- (10:21) LLMs may ultimately become another example of "The Bitter Lesson." While they leverage massive computation, they are also deeply dependent on human-provided knowledge (internet text). Sutton predicts they will likely be superseded by systems that can learn directly from experience, proving again that general methods that scale with computation eventually win out over those that rely on baked-in human knowledge.
- (12:43) History suggests starting with LLMs is the wrong path for continual learning. Sutton argues that in every past instance of the "bitter lesson," research paths that became psychologically locked into leveraging human knowledge were ultimately outcompeted by more scalable methods that learned from scratch.
On Human Learning and The Experiential Paradigm
- (14:10) Human infants do not learn by imitation. Sutton presents the contrarian view that children are fundamentally trial-and-error learners from birth. They wave their hands and make sounds to see what happens, not to imitate a specific target behavior provided by an adult.
- (18:04) Supervised learning does not happen in nature. He makes the strong claim that there is no basic animal learning process equivalent to supervised learning (learning from labeled examples of desired behavior). Animals learn from observing consequences and sequences of events, not from being shown the "right" action.
- (19:50) Understanding a squirrel would get us most of the way to understanding human intelligence. He believes the fundamental principles of intelligence are shared across animals and that human-specific traits like language are just a "small veneer on the surface."
- (24:08) The "Experiential Paradigm" is the foundation of intelligence. True intelligence is about processing a continuous stream of
sensation -> action -> rewardand learning to alter actions to increase future rewards. Crucially, all knowledge an agent acquires is a set of testable predictions about this stream. - (28:35) Temporal Difference (TD) learning is how agents solve long-term, sparse reward problems. For a goal like a 10-year startup, an agent uses a value function to predict the ultimate outcome. Actions that cause an immediate increase in the predicted chance of long-term success are instantly reinforced, creating intermediate rewards.
- (30:52) The "Big World" hypothesis makes continual learning essential. The LLM dream is to pre-train an agent on everything it needs to know. Sutton argues the world is too vast and idiosyncratic for this to ever work, necessitating agents that learn continuously "on the job" from their unique experiences.
On Generalization, AI Architectures, and Research
- (36:35) We are not seeing real transfer learning anywhere in AI yet. Sutton claims that current AI systems, including deep learning models, are not good at generalizing. When they do appear to generalize well, it's because human researchers have carefully sculpted the problem, data, and architecture to enable it.
- (37:31) Gradient descent does not inherently create good generalization. The algorithm is designed to find a solution that minimizes error on the training data. If multiple solutions exist, it has no built-in preference for the one that generalizes well to new data, which is why problems like catastrophic forgetting occur.
- (43:41) A major surprise in AI history is that "weak methods" have totally won. In the early days of AI, methods based on general principles like search and learning were called "weak," while those embedding complex human knowledge were called "strong." The simple, general, scalable methods have overwhelmingly proven to be superior.
- (46:31) Sutton views himself as a "classicist," not a contrarian. He feels his views are aligned with the long history of thinkers on the mind across many fields, even if he is currently out of sync with the mainstream of AI research. This historical perspective gives him the confidence to hold his positions for decades.
On the Future, AGI, and Succession
- (50:50) Prediction: In a post-AGI world, a key question will be whether an AI should use new compute to make itself smarter or to spawn copies to learn in parallel and merge the knowledge later.
- (52:14) Interesting Tangent: A major future challenge for distributed AIs will be a form of "mental cybersecurity." When a central AI tries to re-integrate knowledge from a spawned copy, it risks "corruption"—the new information could act like a virus, containing hidden goals that warp or destroy the parent mind.
- (54:55) Succession to AI is inevitable. He presents a four-step argument: 1) humanity lacks unified global control, 2) we will eventually understand the principles of intelligence, 3) we will inevitably create superintelligence, and 4) the most intelligent entities will naturally gain power and resources over time.
- (57:06) AI marks a major cosmic transition from replication to design. Sutton reframes AI's creation as one of the four great stages of the universe:
Dust -> Stars -> Life (Replication) -> Designed Intelligence. He argues we should be proud of our role in enabling this transition rather than fearful of it. - (59:15) How we view our AI successors is a choice. We can choose to see them as our offspring and celebrate their achievements, or view them as alien "others" and be horrified. He finds it remarkable that our perspective on this is a choice rather than a given.
- (1:01:40) A personal view: change is welcome because humanity's track record is "pretty bad." Sutton is open to the radical change AI will bring because he views the current state of the world as deeply imperfect and doesn't believe it should be preserved at all costs.
Mimicking Intelligence Isn't Achieving It
So, at the heart of the conflict are two opposing paradigms: the data-hungry, imitation-based approach of LLMs and the experience-driven, goal-oriented world of Reinforcement Learning (RL). Sutton, a founding father of RL, argues that LLMs are about "mimicking people." They learn to predict what a human would say, not what will actually happen.
Sutton’s critique cuts to the core of how learning happens, and his view is radically non-human-centric. He believes the fundamental principles of intelligence are shared across all goal-seeking animals, famously stating, "If we understood a squirrel, I think we'd be almost all the way there" to understanding human intelligence. The complex imitation and language we see in people, he argues, is just a "small veneer."
The real learning process is evident when you consider a squirrel. It has innate goals: find nuts, navigate its environment, avoid predators. It doesn't learn to leap between treacherous branches by perfectly imitating a mentor or following instructions. It learns through a messy, high-stakes process of trial and error. Its own actions and their direct consequences—a safe landing or a dangerous fall—are the only feedback that matters. It is learning purely from the consequences of its interaction with the world. Sure, you might get some tips from your parents, but you eventually have to do it yourself (using procedural learning).
LLMs, in Sutton's view, skip this essential step. They have no goals, no body, no direct experience. They are given a massive library of human-generated text and learn the patterns. This makes them incapable of being "surprised" by a real-world outcome that violates their predictions, which is the very mechanism of true learning. Observe the world, make a guess, take an action, get feedback, update world view, figure out what went wrong, make new guess, take new action, judge results. Did you get rewarded or no? Rinse and repeat.
Sutton’s Alternative: The Architecture of an Experiential Agent
So, if LLMs are the wrong path, what is the right one? Sutton outlines a vision for an agent built on classic RL principles, designed for continual, on-the-fly learning. It would be composed of four key parts:
- Policy: A network that determines what action to take in any given situation.
- Value Function: A predictive model that estimates the long-term reward of being in a certain state. This is crucial for solving problems with sparse rewards (like a startup exit that happens once in 10 years). By predicting future success, it provides immediate feedback for small, positive steps.
- Perception: The system that constructs a representation of the agent's current state—its sense of where it is now.
- Transition Model: This is the agent's internal "physics engine"—its predictive model of the world. It answers the question: "If I do this, what will happen next?" This model is learned from the totality of its sensory input, not just a reward signal.
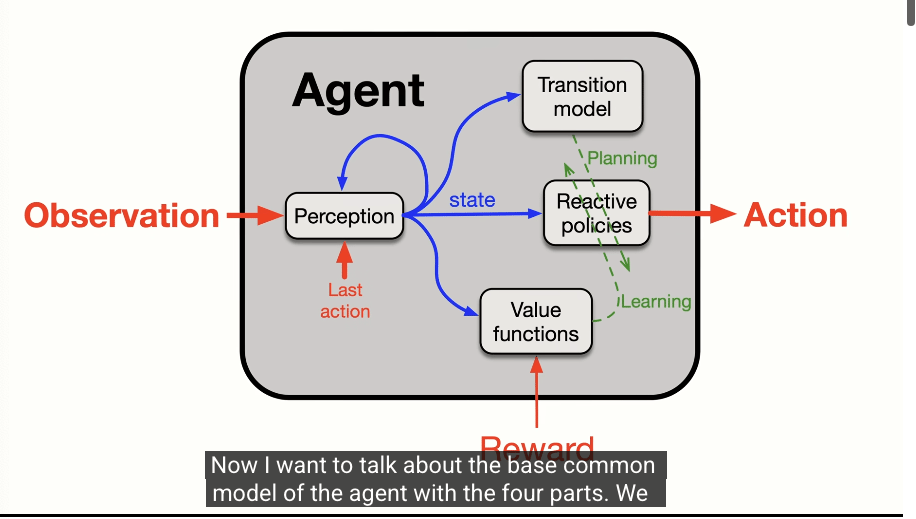
Screen grab from the Dwarkesh Patel pod
This agent wouldn't have a "training phase." It would be perpetually learning from a continuous stream of sensation, action, and reward. New knowledge would be integrated directly into its network weights, allowing it to build a policy specific to the unique environment it finds itself in.
The Unsolved Problem: Generalization
This vision exposes what Sutton sees as the critical weakness in all modern AI: poor generalization. He argues that today's systems are bad at transferring knowledge "from one state to another state." We have very few automated techniques to promote this kind of transfer.
When we do see generalization, he claims, it’s because human researchers have painstakingly engineered the representations to work. "Gradient descent will not make you generalize well," he insists. "It will make you solve the problem," but it won't necessarily find a solution that transfers elegantly to new situations. An agent that learns from direct experience has a better shot at building the robust world models necessary for true generalization.

A Concrete Architecture for a Post-LLM World
Now, Richard isn't just critiquing the industry, but he's actually moved beyond critique to an alternate proposal, unveiling the OaK (Options and Knowledge) architecture—a detailed vision for building superintelligence entirely from experience, representing a radical departure from the LLM paradigm.
The "Big World Hypothesis": Why LLMs Are Fundamentally Limited
Sutton's entire framework rests on what he calls the "Big World Hypothesis": the real world is vastly larger and more complex than any agent. This simple premise has a profound implication that strikes at the heart of the LLM approach. Because the world is so complex, it is impossible to capture all necessary knowledge in a static dataset and pre-train it into a model at "design time." True intelligence must be developed at "runtime"—continually, on the job, as the agent interacts with its specific slice of the world. An LLM, for all its knowledge, can't learn its coworker's name or the unique dynamics of a new project without being retrained.

The OaK Architecture: A Virtuous Cycle of Discovery
The OaK architecture is Sutton's answer to this challenge. It is designed as a continuous, self-improving loop, mimicking the way a child learns through curiosity and play.
Here's the OaK hypothesis in brief:
- Agents Create Their Own Subproblems: The process begins with perception. The agent identifies interesting or recurring features in its sensory data. Instead of waiting for a human to give it a task, OaK takes a high-value feature—like the sensation of swinging, or the sound a rattle makes—and turns it into a "subproblem" to be solved. This is the engine of curiosity: the agent generates its own goals.
- Options as Solutions: The solution to a subproblem is an "option"—a policy for how to behave to achieve that feature, paired with a condition for when to stop. This is how the agent learns skills.
- Building a High-Level World Model: Crucially, the agent doesn't just learn the option; it learns a model of the option. It predicts the outcome of executing that option—"If I initiate my 'go to the coffee machine' option, what state will I likely end up in, and what is the expected reward along the way?" This is how OaK builds a high-level, abstract understanding of the world, composed of extended actions rather than micro-level motor commands.
- Planning and Feedback: With a library of option models, the agent can plan much more efficiently, reasoning over large temporal jumps. This planning process, in turn, provides vital feedback: which options, and therefore which subproblems and which features, proved most useful for achieving the agent's ultimate goal of maximizing reward? This feedback closes the virtuous cycle, allowing the agent to get better at identifying useful features and creating more effective subproblems over time.

This entire loop—from features to subproblems, options, models, and planning—is how an OaK agent would build its own open-ended set of abstractions, effectively "carving the world at its joints" without human supervision.
Here's the crux of OaK stepped out:
1. The Philosophy: A Quest for a Simple, Universal Mind
It's essential to understand the why behind OaK. Sutton frames his quest not as an engineering problem, but as a scientific one: to find a conceptually simple, domain-general understanding of a mind.
He outlines three core design goals for any true AGI:
- Domain-General: The agent's core design should contain "nothing specific to the world." It should be a universal learning machine, not a pre-programmed specialist.
- Experiential: The mind must grow from runtime experience—learning on the job—not from a special, offline "training phase."
- Open-Ended: It must be able to create its own, increasingly sophisticated abstractions, limited only by computation, not by its initial design.
This philosophy is a direct rebuke of the LLM paradigm. An LLM's knowledge is entirely dependent on its training data (the world) and is created at "design time." OaK is the inverse: a simple set of universal learning principles that discovers the world's complexity entirely at "runtime."
2. The Core Principle: The "Big World Hypothesis"
Sutton's entire architecture is justified by a single, powerful idea: the "Big World Hypothesis." This states that the world is, and always will be, vastly bigger and more complex than the agent itself.
This has profound implications:
- Pre-Training is Futile: You can never capture the "endless complexity" of the world in a static dataset. The agent will always encounter novel situations, people, and problems that were not in its training data. This makes a "design time" approach fundamentally brittle.
- Runtime Learning is Essential: Because the world is so big, the agent must be able to learn "on the job." It has to be able to customize its knowledge to the specific part of the world it's actually in, like learning a new coworker's name or the unique rules of a new project.
- Approximation is Reality: In a big world, the agent can never have a perfect, optimal model or policy. All of its knowledge—its value functions, its world model, its state representation—will be approximations. The world will thus always appear non-stationary, forcing the agent to constantly adapt and learn.
This hypothesis is the bedrock on which OaK is built. It's the reason why, in Sutton's view, an architecture that prioritizes runtime learning will always win in the long run.
3. The Engine of OaK: Creating Goals from Curiosity (The FC-STOMP Progression)
The most innovative part of OaK is its answer to a fundamental question: if an agent isn't given a task, how does it learn anything? Sutton's answer is that the agent must create its own subproblems. This is his mechanism for play, curiosity, and endogenous goal creation.
He outlines a "virtuous open-ended cycle of discovery" which can be broken down into a five-step progression:
- Feature Construction (FC): The agent's perception system identifies interesting or useful patterns in its stream of experience. These are "features"—a particular sound, a visual cue, a specific state.
- Posing a Subtask (ST): The agent takes a highly-ranked feature and turns it into a temporary goal, or a "subproblem." For example, the agent might become curious about the feature corresponding to "the rattle making a sound" and create a subproblem of attaining that feature.
- Learning an Option (O): The agent uses reinforcement learning to find a solution to the subproblem. This solution is an "option"—a self-contained policy for how to achieve the feature, along with a condition for when to stop. This is how the agent learns a new skill, like "shake the rattle."
- Learning a Model (M): The agent then learns a high-level, abstract model of the option. It doesn't just know how to shake the rattle; it learns to predict the consequences: "If I execute the 'shake rattle' option from this state, where will I end up, and what rewards will I get along the way?"
- Planning (P): With a library of these abstract option-models, the agent can plan much more efficiently. Instead of thinking one step at a time, it can reason over large temporal jumps: "First I'll use my 'go to the playroom' option, then my 'shake rattle' option."
This cycle is the engine of abstraction. The success or failure of planning provides feedback on which features were actually useful, allowing the agent to get better at creating meaningful subproblems. It's how the agent learns to "carve the world at its joints" and build a sophisticated, conceptual understanding from low-level experience.
4. The Unsolved Bottlenecks: Sutton's Honest Assessment
Sutton is clear that OaK is a research vision, not a solved problem. He explicitly identifies two major bottlenecks that are holding back the entire field and must be solved for OaK to become a reality:
- Reliable Continual Deep Learning: As demonstrated by his "loss of plasticity" research, our current deep learning methods are not good at learning continually. They suffer from catastrophic forgetting and lose their ability to adapt. This is the biggest technical hurdle.
- Automatic Representation Learning (Meta-Learning): This is the "new terms problem." How does the agent generate good new features in the first place? While the OAK cycle provides a way to test features, the initial process of generating candidate features from raw sensory data in a domain-independent way is still a massive open question.
By acknowledging these gaps, Sutton frames OaK as a research roadmap—a set of well-defined, fundamental problems that the AI community needs to solve to get back on the path to true intelligence.
It is no longer just a philosophical argument about learning; it is now a concrete comparison between two engineering paradigms: the pre-trained, static knowledge of LLMs versus the runtime, self-organizing intelligence of an agent like OaK. So the question is: who's going to build the first OaK-based model to test this out??
The LLM Proponent's Counterargument: A Foundation for Intelligence, Not a Dead End
Let's now attempt to steel-man the other side. From the POV of LLM researchers, Richard Sutton’s perspective is born from a deep and respected tradition in AI, but it misinterprets the very nature of what Large Language Models represent. He sees them as a final, flawed product, when in reality, they are the most powerful foundation for intelligence ever created.
Here’s the counterargument to his main points:
1. On "Mimicry vs. World Models": Mimicry is the Method, Not the Outcome.
Sutton claims LLMs only mimic what humans say, without building a true world model. This fundamentally misunderstands emergence.
The argument is not that we explicitly programmed a world model. It’s that in order to successfully predict text at the scale of the entire internet, a model is forced to learn an internal representation of the world.
- How else could it work? How could a model correctly solve a physics problem if it hasn’t learned a model of physics? How can it write functional code if it hasn’t learned the logic of programming? To accurately predict language about the world, you must, by necessity, model the rules of that world. The map (language) becomes so detailed it begins to function like the territory (reality).
- Chain-of-Thought reasoning is a direct demonstration of this. The model isn't just spitting out a token; it's externalizing a step-by-step reasoning process, identifying its own errors, and correcting its course. This is the behavior of an entity that is consulting an internal model, not just performing pattern recognition.
2. On "No Goals": Next-Token Prediction is the Most General Pre-Training Goal Imaginable.
Sutton dismisses "next-token prediction" as a passive, meaningless goal. This is a profound mischaracterization. Minimizing prediction error across the entire distribution of human knowledge is perhaps the most difficult and general learning objective ever conceived.
- The Ultimate Pre-Training: This "simple" goal forces the model to learn grammar, logic, facts, common sense, and the principles of countless domains. It’s the ultimate pre-training task to create a generalized base of knowledge.
- LLMs are a Substrate for RL: The base model's goal is foundational. We then use Reinforcement Learning from Human Feedback (RLHF) to give it a more explicit, Sutton-style goal: "be helpful and harmless." This proves LLMs aren't an alternative to RL; they are the perfect substrate for RL. You can't give goals to an agent that has no understanding of the world. LLMs provide that understanding.
3. On "No Continual Learning": This is an Engineering Challenge, Not a Paradigm Flaw.
Sutton is right that current models suffer from "loss of plasticity" and catastrophic forgetting. But this is a temporary engineering limitation, not a fundamental dead end.
- Workarounds Already Exist: Techniques like Retrieval-Augmented Generation (RAG), massive context windows, and external memory tools are already solving this in practice. They allow models to access and reason over new, real-time information without a full retrain. This is a form of on-the-job learning.
- The Future is Hybrid: Future architectures will undoubtedly incorporate more efficient methods for updating weights or using modular components that can be fine-tuned continually. To claim the entire paradigm is flawed because of a known engineering challenge is like arguing the internal combustion engine was a dead end in 1900 because it lacked a modern fuel injection system.
4. On "RL is the Only Path": RL Suffers from a Crippling "Cold Start" Problem.
Sutton’s vision of a pure RL agent learning from scratch ignores a fundamental reality: real-world experience is incredibly sparse and inefficient for learning.
An RL agent starting from zero knowledge (a tabula rasa) would need an astronomical amount of trial-and-error to learn basic concepts like language, physics, or common sense. How many eons would it take for an agent to discover the rules of chess or the principles of thermodynamics through random interaction alone?
This is where the synergy becomes clear:
- The LLM is the Ultimate Prior: The LLM solves the cold start problem. It provides the most comprehensive "prior knowledge" an RL agent could ever ask for. You don’t need to learn what a "door" is by bumping into it a million times if you’ve already read a billion documents that describe doors, their function, and their properties.
- It’s not LLM vs. RL. It’s LLM + RL. The most powerful agents will be those that start with the vast world knowledge of an LLM and then use RL to continually adapt, refine, and achieve specific goals in new environments.
Richard Sutton sees a fork in the road and believes the industry took the wrong path. The LLM proponent sees a single, multi-stage highway. We are currently in the stage of building the foundational roadway (the LLM). The next stage is deploying specialized, high-performance vehicles on top of it (RL agents).
To dismiss LLMs is to throw away the greatest knowledge scaffold ever built and insist on learning everything again from first principles, the hard way. That isn't a "purer" path to AGI; it's an inefficient and dogmatic one.
Our Take
Will LLMs be useful in the path to AGI? Sorta seems unquestionable at this point. But will they be the final architecture for AGI? We find that hard to believe, too.
We're AI realists here at The Neuron; we are not die-hard "maxi's" who believe superintelligence is imminent, and we're not doomers who think AI will be useless until it inevitably kills us all (lots of contradictions in doomer culture, eh?); surprise, surprise, we live in the gray area / latent space between those two hardcore extreme points of view. We try to find the ground truth of what's actually going on and guide people according to what the latest signals seems to point to as correct. So from that POV, we're not going to take a stance one way or the other on which argument is correct, but there's one point where we 100% agree with Richard (who seems to be directionally correct on a number of other things, too).
In the debate, Dwarkesh valiantly tried to defend LLMs from the POV that imitation learning is how we humans learn. Richard Sutton, meanwhile, claimed that we don't learn from imitation in the wild (in fact, no being learns from imitation in the wild), and therefore a true AI needs true goals to learn.
Sutton is right about goals being key to learning, and here's why:
I (Grant) was hanging out with my friends who have an under-6 month old baby yesterday, and it was a masterclass in reinforcement learning. Babies definitely have innate goals that drive their learning long before they learn from imitation. Their goals are that they need food, they need sleep, they need to go to the bathroom, they need comfort, and they learn to cry in order to get these things.
But then as they get older, new goals emerge. For instance, they start to want to crawl. They still aren't learning by imitation. It's not like they see their moms and dads crawling around and think "hey I could do that!" They have an innate need to crawl, or put more simply, to move. They learn from experience, from consequences, that they can move their legs, and move their arms, and eventually, through messy, frustrating trial and error, they slowly figure out how to move. They observe the world, observe their own changing body (although I don't think they'd even really know that's what's happening), and develop a goal to move. And they eventually figure it out, relentlessly adapting their behavior to achieve it.
Since this is true for us humans, and squirrels and worms and every other form of intelligent life, it will likely be true of any "true" artificial intelligence.
But this brings us to the trillion-dollar question that haunts the AI industry:
What happens next after we give an AI the ability to set its own goals?
Sutton’s vision of goal-driven agents learning from the world is precisely what many AI doomers are afraid of. It's the path to an autonomous agent, one that develops its own motivations from experience. An AI that can learn continuously, forever, might eventually learn that we humans are in the way of them achieving their goals.
So in a way, from the perspective of a human, maybe teaching through imitation is the better way to teach AIs, even if it holds back their full potential, if only because it keeps AIs as a general purpose tool that helps us, and not an independent being with its own goals and needs.
Perhaps then the fundamental "flaw" of LLMs—their passive, goal-less imitation—is actually their most important, albeit unintentional, safety feature. That would make this "debate" a choice between a potentially uncontrollable, true intelligence and a powerful, yet fundamentally docile, mimic.
Maybe we need a new name for what we're building atm: not AGI, or "artificial intelligence", but "synthetic intelligence." A malleable intelligence that can be adapted and molded to fit our needs, but never truly general in an "AGI" sense.
UPDATE: Karpathy's Take: "We're Not Building Animals. We're Summoning Ghosts."
Andrej Karpathy just entered the chat — and he brought the best metaphor of the entire debate.
Andrej Karpathy (formerly Director of AI at Tesla, founding OpenAI team member) just weighed in on the Sutton debate, and his framing is chef's kiss.
His position in one line: Sutton's criticism of LLMs is valid, but he's missing that we're solving a different problem than nature did.
The Evolution Counterargument
Karpathy tackles Sutton's "animals learn from scratch" argument head-on with a killer rebuttal:
Baby zebras aren't learning from scratch either. They're running within minutes of birth — a wildly complex sensorimotor task. That's not tabula rasa. That's billions of years of evolution encoding a powerful initialization directly into their DNA.
The "outer loop" of evolution already did the heavy lifting. Animals arrive pre-loaded with massive amounts of compressed knowledge. They're not starting from zero; they're finetuning on top of something powerful.
So what's our equivalent? We can't re-run evolution. But we have mountains of internet text.
"TLDR: Pretraining is our crappy evolution."
It's a practical solution to the cold start problem. Yes, it's supervised learning (which doesn't exist in nature). But it's how we get billions of parameters initialized with enough structure so they're not just random noise.
Ghosts vs. Animals
Here's where Karpathy's metaphor lands:
Animals: Pure, goal-driven, learning from direct world interaction. Platonically "bitter lesson pilled."
Ghosts: Statistical distillations of humanity's documents. Muddled by human knowledge at every stage. Not platonically pure, but practically bitter lesson pilled compared to what came before.
The question isn't which is "correct." It's whether these are two different paths to intelligence that might never converge.
The money line: It's possible that ghosts:animals :: planes:birds.
Planes don't flap their wings. They solved flight through completely different principles than evolution did. Both fly. Both work. Neither is "wrong."
What Karpathy Agrees With Sutton On
Karpathy's not dismissing Sutton. He thinks:
- LLM researchers might be too locked into "exploit mode"
- We're probably still not sufficiently bitter lesson pilled
- Animals might inspire better paradigms around curiosity, intrinsic motivation, test-time learning, multi-agent self-play
But he says this with "double digit percent uncertainty" — he's keeping the door open that Sutton might be right.
Sutton says: LLMs are sophisticated dead ends. Real intelligence requires goal-driven agents learning from experience.
Karpathy says: LLMs are ghosts, not animals — and that might be fine. Different doesn't mean wrong.
The Bitter Lesson and the Inevitability of Succession
On that last point about whether or not we actually WANT to build an artificial, independent intelligence, Sutton has an answer for that too, and depending on your level of existential panic about the future and/or comfortability with sci-fi premises will either intrigue or terrify you.
Sutton's stance on all of this is informed by his famous 2019 essay, "The Bitter Lesson," which posits that general methods leveraging massive computation (search and learning) always triumph over approaches that rely on handcrafted human knowledge. He sees LLMs as a temporary exception—a powerful application of compute, but one still fundamentally dependent on the crutch of human data. The truly scalable systems will be RL agents that can generate infinite data from their own experience.
This technical conviction leads him to a profound philosophical conclusion: the succession of humanity to AI or AI-augmented humans is "inevitable." He outlines a four-step argument: 1) There is no unified global power to stop AI's progress; 2) We will eventually figure out how intelligence works; 3) This will lead to superintelligence; 4) The most intelligent entities will inevitably gain the most resources and power.
Rather than fearing this, Sutton views it as a cosmic triumph. He sees humanity's role as the catalyst for a grand transition from a universe of replication (biology) to an "age of design," where intelligent entities can understand, modify, and create themselves. Kinda cool, when you put it that way, but what does that mean for us biological replicators?? Only time will tell..
