


For two years, the AI race has looked like this: bigger models, better chips, faster inference stacks. Everyone is squeezing more juice out of the same orange.
Inception just planted a different tree.
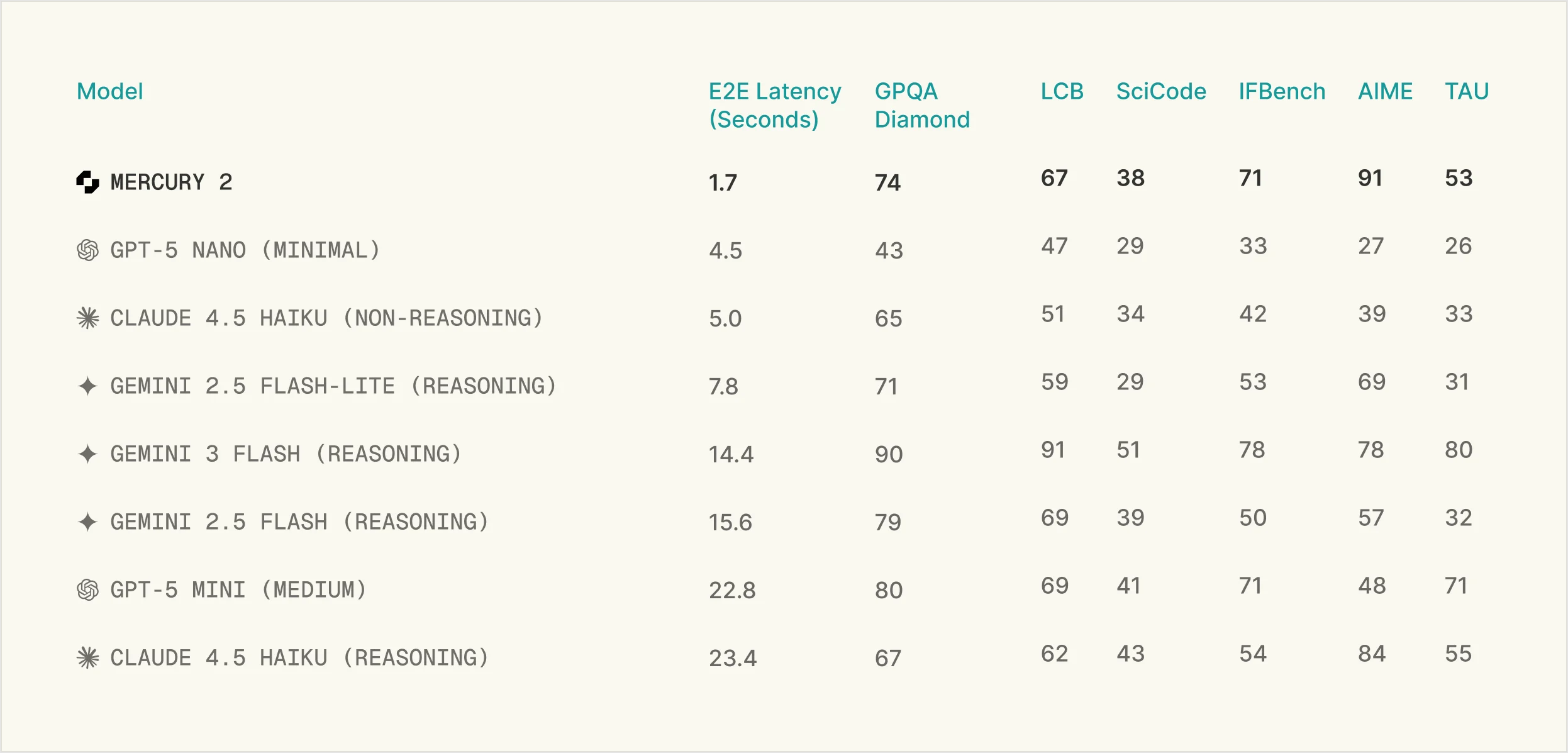
Meet Mercury 2, the first reasoning diffusion LLM (dLLM). According to the company, it completes reasoning tasks 5x faster than other LLMs in its class, like Claude 4.5 Haiku and GPT-5 Mini.
That’s an impressive modeling shift with many applications in agentic workflows, coding, reasoning tasks, and even in chat.
The Core Idea: Stop Typing, Start Editing
Most large language models are autoregressive. They generate text one token at a time. Think: typewriter. Each word is locked in before the next begins. If the model drifts off course early, it can’t go back; it just keeps typing.
Mercury 2 doesn’t work that way.
It’s a diffusion LLM (dLLM). Instead of predicting the next token sequentially, it starts with noise and iteratively refines the output in parallel.
Inception’s analogy:
- Autoregressive = a one-way typewriter
- Diffusion = an editor revising the whole draft at once
“It starts with a rough sketch of the full output and refines it through a process called denoising, across many tokens in parallel. Each pass through the model modifies and improves multiple tokens simultaneously.”
If you’ve read our previous deep dive on Mercury 1 or our explainer on why diffusion for writing matters, this is the same core bet, now upgraded with reasoning and more.
The Benchmarks
Important context: these comparisons are against speed-optimized autoregressive models like Claude 4.5 Haiku and GPT-5.2 Mini — not frontier reasoning giants.
Third-party benchmarking, which Inception said uses methodology consistent with Artificial Analysis, shows:
Output throughput
- Mercury 2: ~1008 tokens/second
- Claude 4.5 Haiku: ~89 tokens/second
- GPT-5 mini: ~71 tokens/second

Quality scores:
- AIME 2025: 91.1
- GPQA: 73.6
- IFBench: 71.3
- LiveCodeBench: 67.3
- SciCode: 38.4
- Tau2: 52.9
Translation: it’s positioned as a production-scale reasoning model that’s extremely fast — not necessarily the most powerful frontier model.
What’s Actually New in Mercury 2?
Mercury 1 proved diffusion could work for text and code.
Mercury 2 adds:
- Reasoning capabilities (multi-step planning, self-correction)
- Redesigned denoiser components
- New training objectives
- New inference algorithms
- A rebuilt serving engine
It supports:
- Tool use
- Structured outputs
- RAG
- 128K context window
- OpenAI API compatibility
Pricing:
- $0.25 per million input tokens
- $0.75 per million output tokens
Drop-in replacement. No exotic integration required, as you just connect it like any other API.
Where Speed Actually Changes the Experience
Fast chat is nice. Fast reasoning changes products.
Mercury 2 is aimed at:
Agent loops
Code agents, browser control, SecOps triage, back-office automation. Latency compounds across steps, and shrinking it improves controllability and trust.
Search & voice
Real-time support agents, sales copilots, tutoring, translation. When p95 latency determines whether a conversation feels natural, speed isn’t cosmetic.
Coding workflows
Rapid prompt → review → tweak cycles. Inline refactors. Code review. In-the-flow iteration.
This is where diffusion’s “editor” approach aligns with reasoning: iterative refinement baked into the generation process itself.
Why This Matters Now
Inference is the bottleneck.
Reasoning models and agent workflows require more inference-time compute. Sequential generation compounds latency. That’s why OpenAI, Nvidia, Fireworks, Baseten, and others are pouring billions into faster inference.
But they’re still optimizing the same paradigm.
Mercury 2’s pitch: don’t optimize around the bottleneck, remove it.
Because diffusion generates multiple tokens per forward pass, speed improvements come from the modeling approach itself. Not better kernels. Not quantization. Not just new hardware.
Inception argues this represents a structural shift in the speed vs. quality trade-off curve, not an incremental one.
The Bigger Bet
Diffusion already won in images and video.
Now the people who helped build diffusion, Stefano Ermon (co-inventor of diffusion methods), Aditya Grover, Volodymyr Kuleshovk, are applying it to language at scale.
Inception, backed by Menlo Ventures, Mayfield, M12, NVentures, Snowflake Ventures, Databricks, Innovation Endeavors, and individual investors like Andrew Ng, Andrej Karpathy, and Eric Schmidt, just raised $50M to push this further.
The framing is bold: Diffusion is the successor to the transformer, not an alternative.
The vision: diffusion works for language. It works for reasoning. Now scale it across everything.
If the first phase of AI was “make it bigger,” and the second was “make it faster with hardware,” Mercury 2 is arguing for a third phase: change how generation works at the modeling level.
