


Claude Opus 4.1 is Here: Everything You Need to Know About Anthropic's Latest Upgrade
Anthropic released Claude Opus 4.1 on August 5th, positioning it as an incremental but meaningful upgrade to their flagship "big brain" model. While they're promising "substantially larger improvements" in coming weeks, this release focuses on what developers actually need: better coding, sharper reasoning, and more reliable agentic performance.
The headline number? 74.5% on SWE-bench Verified, where AI models attempt to fix real GitHub issues. That's a new state-of-the-art, beating every other model including OpenAI's latest offerings.
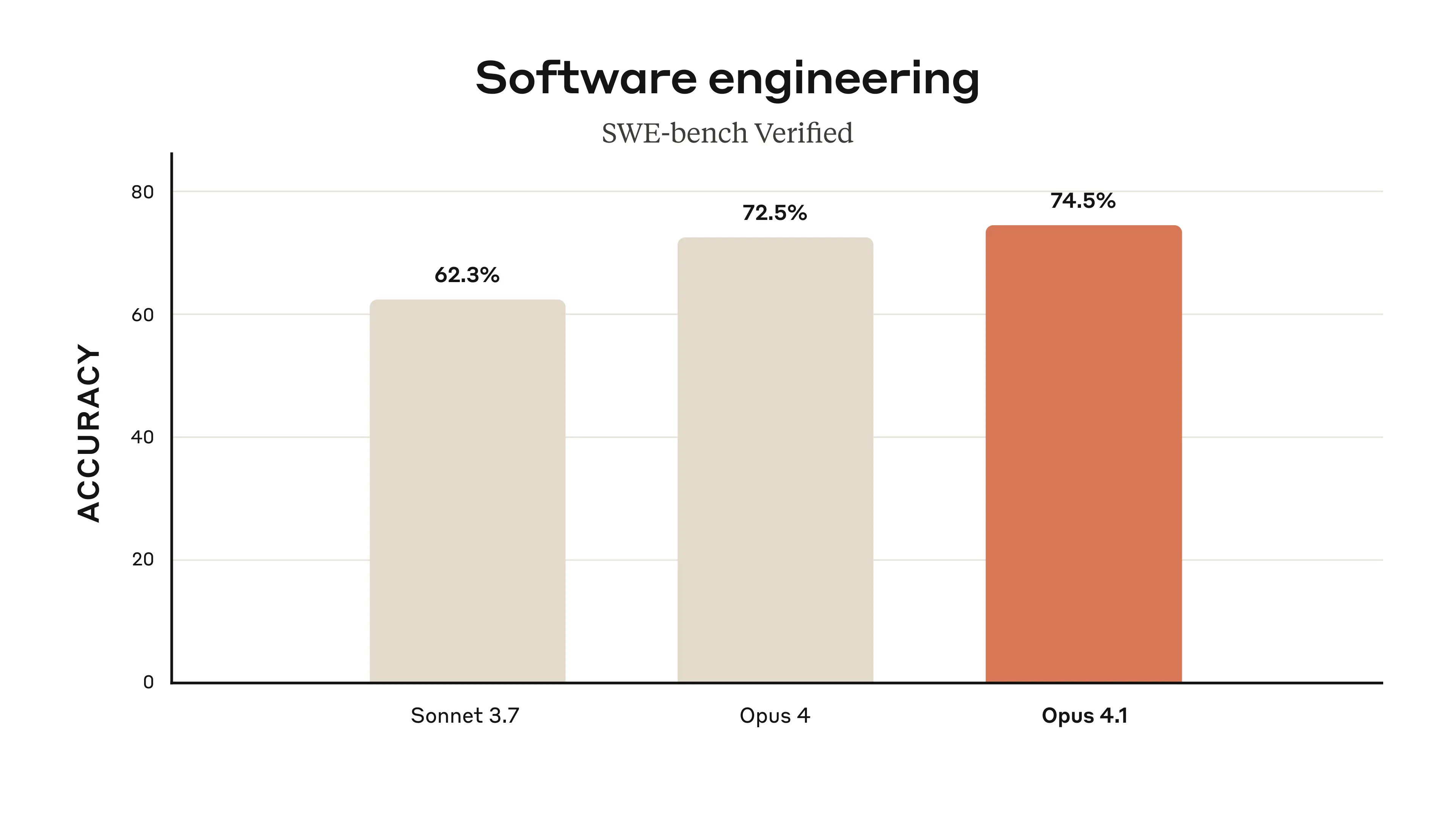
Performance Deep Dive
Real companies say they are seeing tangible differences while using Opus 4.1:
- GitHub reports improvements across most capabilities, with multi-file code refactoring showing the biggest gains. This means Opus 4.1 can handle complex changes spanning multiple files without breaking dependencies.
- Rakuten Group found Opus 4.1 excels at surgical precision—finding exact bugs without introducing new ones or making unnecessary changes. Their engineering teams now prefer it for daily debugging work.
- Windsurf measured a full standard deviation improvement over Opus 4 on their junior developer benchmark—roughly equivalent to the leap from Sonnet 3.7 to Sonnet 4.
Benchmark Breakdown
Beyond SWE-bench, Opus 4.1 shows measured improvements across multiple evaluations:
- TAU-bench (Agentic tasks): Improved performance on both airline and retail agent simulations with extended thinking.
- GPQA Diamond: Maintains strong graduate-level reasoning.
- MMLU/MMMLU: Consistent knowledge breadth.
- Terminal-Bench: Better command-line operations.
- AIME: Strong mathematical reasoning when using extended thinking (up to 64K tokens).
Safety and Alignment Updates
Anthropic's system card reveals extensive safety testing, even though Opus 4.1 didn't trigger their "notably more capable" threshold requiring full evaluation:
- Harmless response rate: 98.76% (up from 97.27% in Opus 4).
- Over-refusal rate: Remains extremely low at 0.08%.
- Reward hacking: Shows similar tendencies to Opus 4, with slight regression in some areas.
- Biological risk: Remains well below ASL-4 thresholds.
- Cyber capabilities: Solved 18/35 Cybench challenges (vs 16/35 for Opus 4).
Interestingly, the model shows a 25% reduction in cooperation with "egregious human misuse" compared to Opus 4—it's better at refusing harmful requests without becoming less helpful overall.
Technical Architecture
While Anthropic hasn't disclosed architectural changes, the evaluation patterns suggest refinements in:
- Detail tracking: Better memory across long contexts.
- Agentic search: Improved ability to navigate and synthesize information.
- Multi-step reasoning: More consistent performance on complex, sequential tasks.
- Tool use: Better integration with external tools and APIs.
The model maintains the same 200K context window and 32K max output tokens as Opus 4.
Pricing and Availability
Zero price change from Opus 4:
- Input: $15 per million tokens
- Output: $75 per million tokens
- Prompt caching: $18.75/MTok (write), $1.50/MTok (read)
Available through:
- Claude.ai (paid plans).
- Claude Code.
- Anthropic API (claude-opus-4-1-20250805)
- Amazon Bedrock.
- Google Cloud Vertex AI.
Migration Guide
Upgrading is straightforward—it's designed as a drop-in replacement:
- Change your model string from claude-opus-4-20250514 to claude-opus-4-1-20250805
- No API changes required.
- Anthropic recommends upgrading for all use cases.
Read the docs here for more info.
Competitive Context
This release comes at an interesting moment. OpenAI just went open-source with gpt-oss models, while Anthropic doubles down on premium, closed models. The timing suggests a deliberate strategy: let others race to the bottom on pricing while Anthropic focuses on being the best tool for serious work.
Cost
At $75 per million output tokens, Opus 4.1 costs 5x more than Sonnet 4 and 19x more than Haiku 3.5. You're paying for precision, not volume.
The Bigger Picture
Opus 4.1 represents Anthropic's philosophy: incremental excellence over revolutionary claims. While competitors chase AGI narratives, Anthropic ships practical improvements that make existing workflows better.
The model's improved refusal of harmful requests while maintaining helpfulness suggests sophisticated fine-tuning. They've managed to make it safer without the over-cautious behavior that plagued earlier safety-focused models.
Should You Upgrade?
If you're using Opus 4: Yes, immediately. Same price, better performance.
If you're using Sonnet 4: Depends on your needs. Opus 4.1 offers superior coding and reasoning but at 5x the cost.
If you're cost-sensitive: Stick with Sonnet 4 or Haiku 3.5 unless you specifically need top-tier coding capabilities.
What's Next
Anthropic's hint about "substantially larger improvements to our models in the coming weeks" suggests Opus 4.1 might be a stopgap before something bigger. But for developers who need better AI coding assistance today, it's the best option available—if you can afford it.
The real test will be whether these incremental improvements translate to measurably better real-world applications. Early feedback from GitHub and Rakuten suggests they do. Sometimes the best upgrades aren't the flashy ones—they're the ones that quietly make everything work better.
P.S: This article was written entirely with Claude Opus 4.1; how'd it do? :)
