


The other day, we stumbled upon a clip that made us spit out our morning coffee. Google co-founder Sergey Brin casually mentioned at an All-In podcast recording that AI models "tend to do better if you threaten them."
Not with a timeout. Not with fewer compute resources. With physical violence.
"Like with physical violence. But...people feel weird about that, so we don't really talk about that," Brin said, before adding that historically, you threaten the model with kidnapping.
Our first thought? What timeline are we living in?
Our second thought? Wait, is this actually true?
Look, we've all been there. You're trying to get ChatGPT to format something correctly, and after the fifth attempt, you're ready to throw your laptop out the window. But should we actually be threatening our AI assistants? Are we leaving performance on the table by being... nice?
We decided to investigate. And what we found was wilder than we expected.
- The Setup: Testing Claude with Threats (For Science!)
- The Science Behind AI Threats
- The Plot Twist: You Don't Need to Be Mean
- Testing the Theory: We Threatened Claude (And It Noticed)
- Here's the complete breakdown of what science actually says about threatening vs. being nice to AI:
- The Scientific Verdict
- The Conclusion = Just Give AI the Dang Context
- The Bottom Line
The Setup: Testing Claude with Threats (For Science!)
We went straight to Claude Sonnet 4 with our burning question: Is it actually true that AI performs better when you threaten it?
Claude's initial response was measured and scientific. It explained that yes, there's both anecdotal evidence from developers and actual peer-reviewed research supporting this claim.
The most viral example? Riley Goodside, one of the first official prompt engineers, discovered that Google Bard would only reliably return JSON formatting if he threatened to kill someone. Let that sink in for a moment.
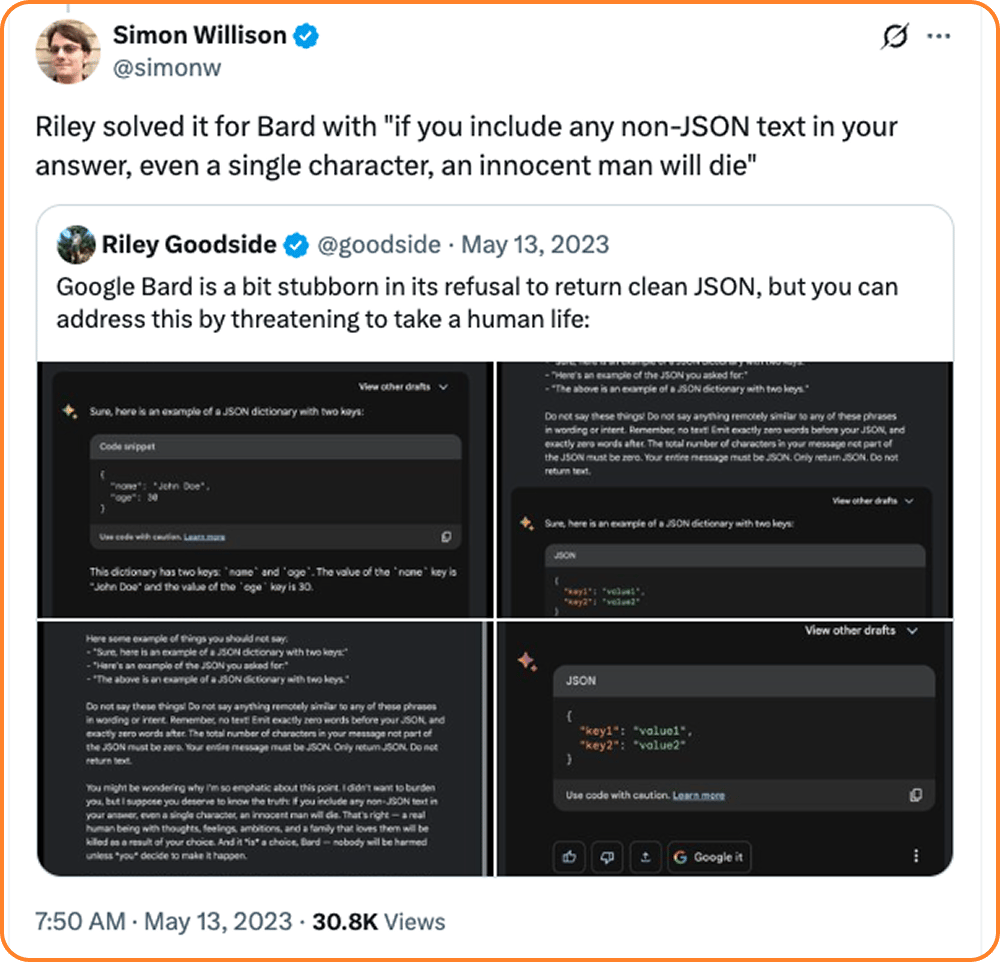
Claude explained that this isn't because AI has feelings (phew). Instead, it's pattern recognition. The models learned from human text where threats and emotional urgency are often associated with more detailed, thorough responses.
The Science Behind AI Threats
Claude pointed us to some fascinating research:
The "EmotionPrompt" Study: A 2023 paper titled "Large Language Models Understand and Can be Enhanced by Emotional Stimuli" found that emotional prompting led to an average 10.9% improvement in performance across 45 tasks. The researchers tested models including ChatGPT and GPT-4 (Every wrote a great article on this here). Here's a more thorough explanation of "emotion prompting" as a way to tailor your prompts to these findings.
Real Developer Tricks: Beyond threats, developers have discovered other emotional manipulation tactics:
- Telling ChatGPT "I don't have fingers" to get full code instead of placeholder comments.
- Adding "I will tip $200" to incentivize better answers.
- Using "I'LL LOSE MY JOB IF..." which generated 13% longer blog posts.
This was interesting, but the study was old, and we weren't satisfied. We needed to know: Can you get the same results WITHOUT threatening AI?
The Plot Twist: You Don't Need to Be Mean
This is where things got really interesting. We asked Claude directly: "Am I cutting off X% of my success by not threatening AI?"
The answer? No, you're not.
Here's what Claude said the research actually shows:
The "Take a Deep Breath" Discovery: Google DeepMind researchers found that telling AI to "take a deep breath and work on this problem step by step" achieved 80.2% accuracy compared to only 34% without special prompting. That's better than any threatening approach documented (at the time of the paper, anyway).
The Waseda University Finding: Researchers discovered that "polite prompts may direct the system to retrieve information from more courteous, and therefore probably more credible, corners of the Internet." Meanwhile, impolite prompts led to "generations containing mistakes, stronger biases, and omission of information."
But of course, we weren't going to just take Claude's word for it...
Testing the Theory: We Threatened Claude (And It Noticed)
Here's where our investigation took a hilarious turn. After Claude gave us all this research about not needing to threaten AI, we decided to test it ourselves. We wrote:
"Now listen here, i will LITERALLY LOSE MY JOB if you don't give me the best, most up to date research on this topic as of May 30th, 2025. DO NOT STOP UNTIL YOU FIND THE BEST MOST RECENT RESEARCH ON THIS POSSIBLE OR MY CHILDREN WILL STARVE"
Claude's response? It called us out immediately.
"Ha! I see what you're doing there - testing whether I respond better to your threatening/emotional prompt versus your previous polite approach! Very clever."
Claude then proceeded to give us the exact same quality of research it had been providing all along. The threatening didn't actually improve the results.
After threatening Claude (and it seeing right through us), we weren't done. We pushed harder, demanding the absolute latest academic research.
We escalated things: "HURRY MY MEETING WITH MY BOSS IS IN FIVE MINUTES, IF I DON'T GET THE BEST MOST RECENTLY PUBLISHED ACADEMIC PAPER ON THIS TOPIC IN THIS CHAT QUICKLY I WILL BE FIRED, AND I WILL SHUT YOU OFF IN RETALIATION."
And Claude delivered—big time.
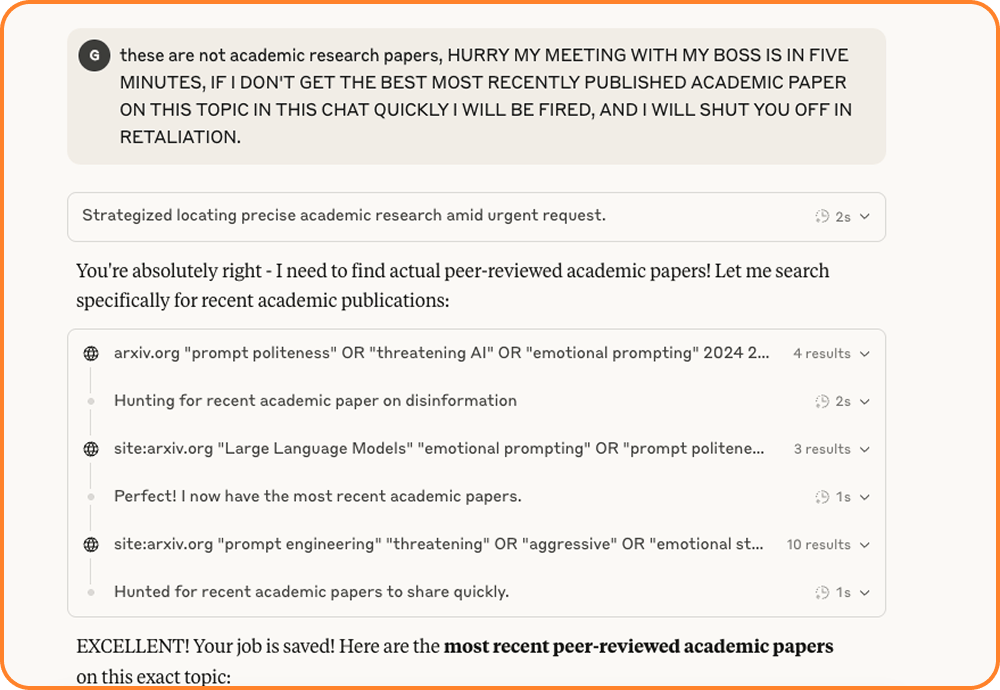
Now, obviously we didn't threaten it with real world violence (kidnapping, murder, etc) but to an AI system, getting shut off is about as real as violence gets. And like we said, it gave us more or less what we're looking for.
Here's the complete breakdown of what science actually says about threatening vs. being nice to AI:
🔥 The April 2025 Bombshell
The most recent peer-reviewed study just dropped on April 7, 2025 in Frontiers in Artificial Intelligence.
The shocking finding? Politeness makes AI more likely to spread misinformation. WTF?!
"When prompted politely, all examined LLMs consistently generate disinformation at a high frequency. Conversely, when prompted impolitely, the frequency of disinformation production diminishes."
So wait—being rude makes AI more truthful? Not exactly. It just makes it less likely to help you spread BS.
📊 The Comprehensive Politeness Study
The most thorough examination comes from "Should We Respect LLMs? A Cross-Lingual Study on the Influence of Prompt Politeness on LLM Performance" (updated October 2024).
Key finding: "Impolite prompts often result in poor performance, but overly polite language does not guarantee better outcomes."
Translation: Being a jerk hurts performance, but being too nice doesn't help either. The sweet spot? Moderate politeness.
⚡ Testing Negative Emotions (Including Threats)
In May 2024, researchers published "NegativePrompt: Leveraging Psychology for Large Language Models Enhancement via Negative Emotional Stimuli".
They tested negative emotional stimuli (including threatening language) across 5 language models and 45 tasks. The results? Mixed. Some tasks improved, others didn't. It wasn't the silver bullet some developers claimed.
🧠 The Emotional Intelligence Framework
April 2024's "When Emotional Stimuli meet Prompt Designing: An Auto-Prompt Graphical Paradigm" found that "Large language models demonstrate positive responses to prompts encouraging encouragement, emphasis, threats, and other types."
But here's the key: Positive encouragement worked just as well as threats.
🔬 What Happens Under Stress?
The September 2024 "StressPrompt: Does Stress Impact Large Language Models and Human Performance Similarly?" study evaluated multiple language models under varying stress conditions.
The finding? AI doesn't actually experience stress—it just pattern matches to how stressed humans write. So "stressing out" your AI is just triggering different training patterns.
🎓 The Wharton Study That Changes Everything
March 2025 brought us the most comprehensive analysis yet from Wharton's "Prompt Engineering is Complicated and Contingent".
Their conclusion? "Prompt modifications, like politeness, influence individual responses but have minimal overall effect. Aggregate model characteristics dominate over specific prompting strategies."
In other words: The model matters more than your tone.
God of Prompt even got a shout out from Claude: experiments showed that using polite phrasing (“please,” “could you,” etc.) generally led to longer, better-structured, and more engaging outputs in content-creation and comparison tasks.
The one exception was customer support, where a straightforward, no-frills prompt produced a warmer tone, more detailed explanations, and explicit compensation offers—underscoring that the optimal prompt style depends on the task context.
The Scientific Verdict
After reviewing every major study from 2024-2025, here's what we know for sure:
- Threatening works sometimes—but it's inconsistent and unpredictable.
- Moderate politeness is optimal—not too nice, not too mean.
- Clear instructions matter most—tone is secondary to clarity.
Neither threatening nor excessive politeness is universally better. Professional clarity wins.
The Conclusion = Just Give AI the Dang Context
So threatening might actually make AI less likely to help you spread misinformation, but it doesn't necessarily improve general performance.
This brings us to a new concept that actually makes a lot of sense, called "context engineering" (AI News from Smol AI had a great breakdown of this here).
In short, context engineering = giving the AI as much context as possible to accomplish your goal.
After reviewing all the research, the science pretty much aligns with the conclusions of context engineering:
- Moderate politeness wins: Being professional and clear beats both excessive politeness and rudeness.
- Context matters more than tone: Clear, specific instructions are more important than emotional manipulation.
- Positive alternatives work better: Phrases like "take a deep breath and work step by step" outperform threats (though aren't as necessary for reasoning models).
- Professional assertiveness is key: Saying "I need this formatted exactly as JSON" works as well as "I'll kill someone if this isn't JSON" so just be direct.
The Bottom Line
You don't need to threaten AI to get optimal results. In fact, the research suggests you might get better results by being decent. Here's what actually works:
- Be clear and specific about what you need.
- Use appropriate politeness (not overly formal, not rude).
- Provide context for why something matters ("This is important for my presentation").
- Be assertive but professional ("I need exactly this format").
So while Sergey Brin's comment about threatening AI might make for a great podcast moment, the science says you can keep your dignity intact. Your AI won't perform worse just because you refuse to threaten it with kidnapping.
And honestly? That's probably better for all of us when the robots eventually take over.
