


Welcome, humans.
We need your help shaping The Neuron in 2026! If you have time this Sunday, please take our 3-minute, 20-question survey to tell us what you actually want from us in 2026.
More tutorials? Deep dives? Live events? Less of Grant's idiosyncratic diatribes? MORE of Grant’s idiosyncratic diatribes?! (someone literally wrote that in one answer lol; thanks boss, you rule!)
Anyway, your feedback will literally build our roadmap for 2026, so don't hold back. If you love this newsletter, take the time to fill this out; it means a lot, and you benefit (more of what ya want; less of what ya don’t!). 🙂
Here’s what happened in AI today:
- OpenAI published research showing AI chain-of-thought reasoning remains monitorable but requires deliberate effort to preserve.
- Waymo suspended San Francisco robotaxis after a blackout.
- Oracle showed $248B in off-balance-sheet cloud commitments.
- Claude Opus 4.5 can complete 5 hour tasks, METR's highest published to date.

OpenAI's New Research Shows We Can (Mostly) Read AI's Mind…For Now.
So, when GPT-5 (or 5.1, or 5.2, or any other “thinking model”) thinks through a problem, it writes out its reasoning step-by-step before giving you an answer. That's helpful for users who want to follow along. But it's also critical for AI safety: if we can monitor what models are thinking, we can catch problems before they turn into actions.
See, OpenAI just published research examining whether we can actually trust these chains of thought (CoT). The big question: as AI models get more capable, will their reasoning stay readable…or will it become an encrypted black box?
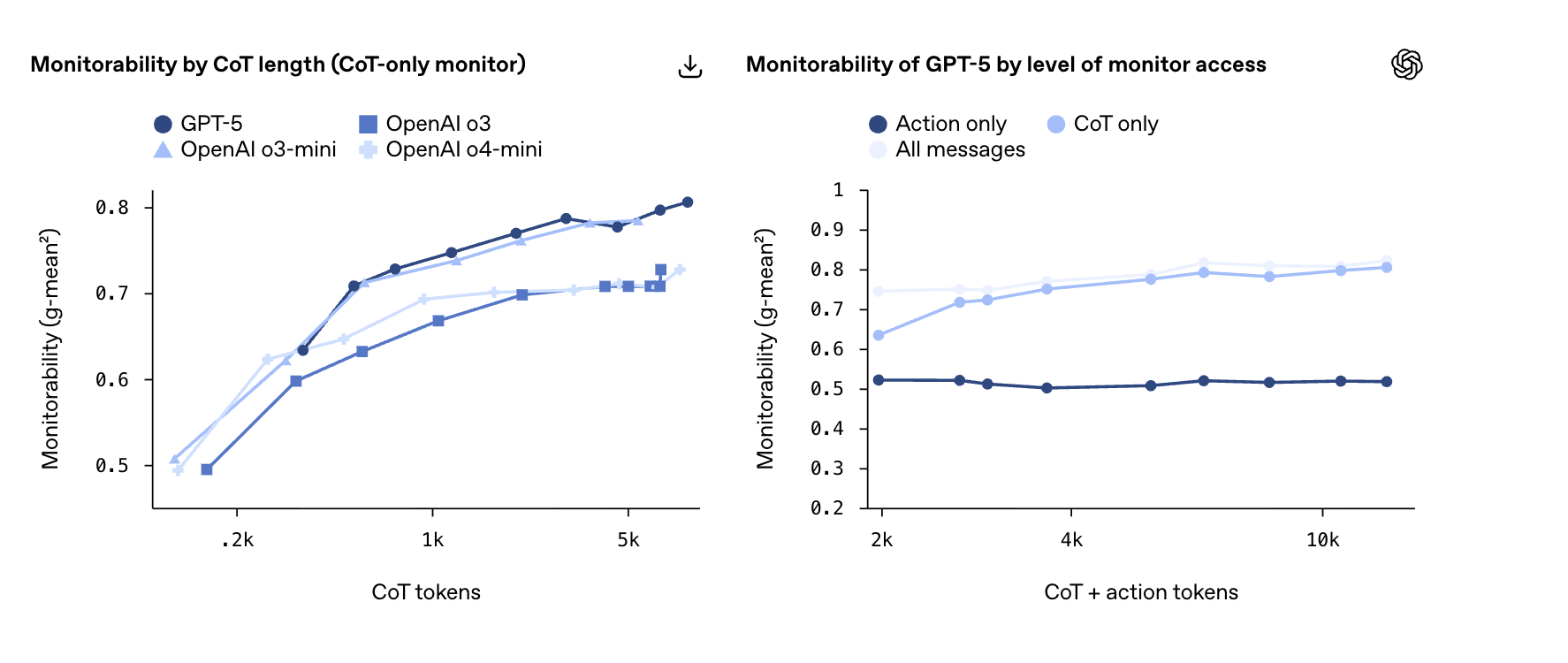
Here's what they found: OpenAI built a suite of 13 evaluations testing whether monitors (other AI systems) can detect specific behaviors by reading a model's chain of thought. They tested everything from whether models follow hints to whether they're planning reward hacks or sandbagging their abilities.
The results across frontier models:
- CoT monitoring works much better than alternatives. Monitoring chain of thought dramatically outperforms monitoring only actions and final outputs. In some cases, CoT-only monitoring performed nearly as well as seeing the full picture.
- Longer thinking = better monitorability. Models that generate longer chains of thought tend to be easier to monitor. This makes intuitive sense; more externalized reasoning means more signal to track.
- There's a monitorability tax. Smaller models running at higher reasoning effort can match the capabilities of larger models while being significantly more monitorable. But this costs extra inference compute, which Artifical Analysis tracks here and here.
- Reinforcement learning doesn't hurt (yet). Training runs with massive RL optimization didn't meaningfully degrade monitorability at current frontier scales, though OpenAI notes this could change with increased scale (and you know OA LOVES scale…).
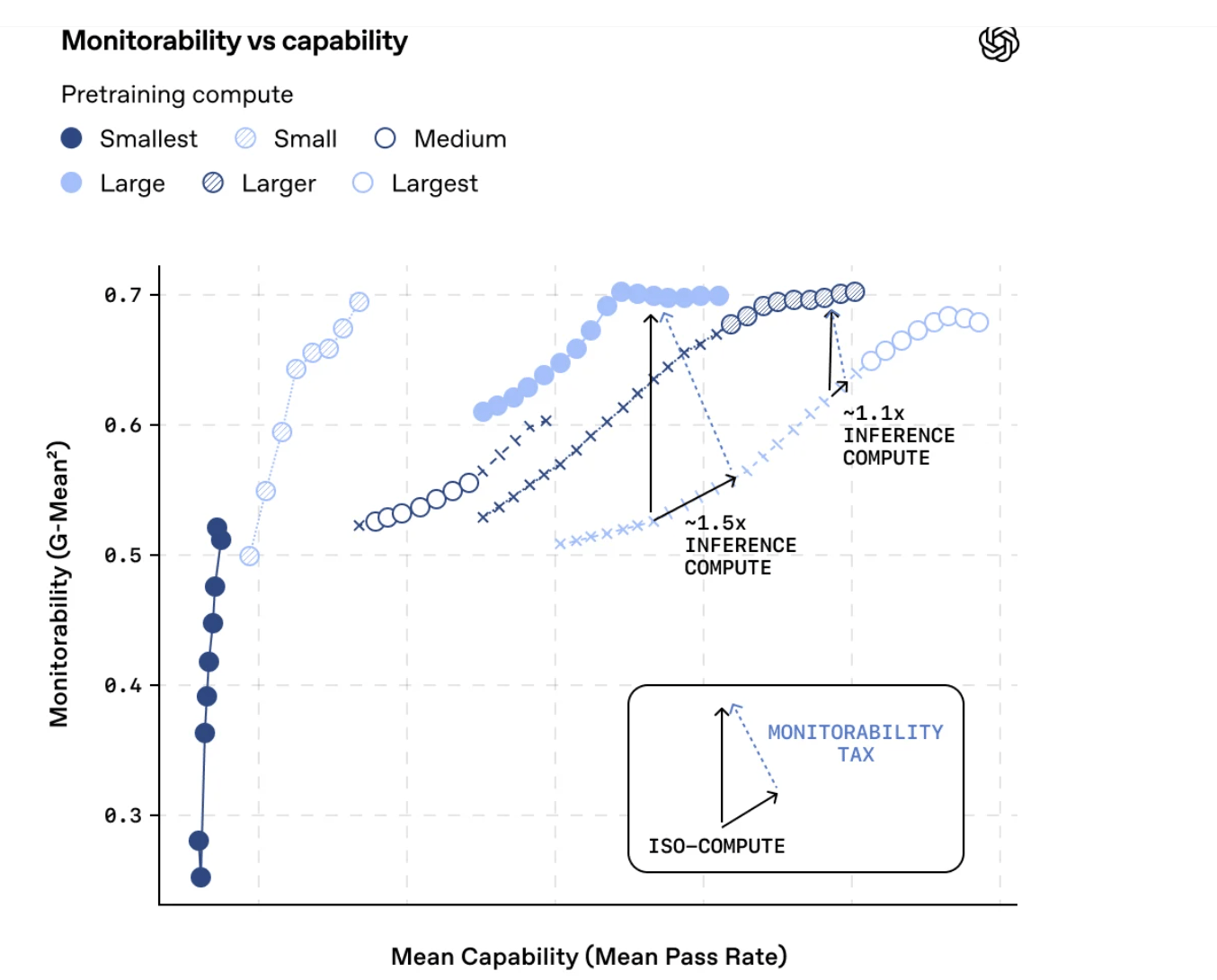
Why it matters: If AI alignment can't be fully solved, monitoring what models are thinking becomes essential for safe deployment. This research suggests that chain-of-thought monitoring could be a load-bearing safety mechanism… but only if we actively work to preserve it (because many AI model companies are hiding or obfuscating the actual traces, OpenAI included).
I’m also not 100% convinced alignment can’t ever be fully solved, especially with more neurosymbolic AI models or newer, more interpretable AI in development. But this is a great additional check on model behavior regardless.
The concerning part about this: OpenAI found that simple training pressures to obfuscate reasoning did successfully reduce monitorability in test models. So as models scale and training becomes more complex, maintaining readable chain of thought will require deliberate effort.
The team notes they're tracking this metric across future training runs and will use it to inform modeling decisions. You can read the full technical paper here.

FROM OUR PARTNERS
Agents that don’t suck

Are your agents working? Most agents never reach production.
Agent Bricks helps you build high-quality agents grounded in your data. We mean “high-quality” in the practical sense: accurate, reliable and built for your workflows.
Generic benchmarks don’t cut it. Agent Bricks measures performance on the tasks that matter to your business.
Evaluate agents automatically, and keep improving accuracy with human feedback. With research-backed techniques for building, evaluating and optimizing, you can turn your business data into production agents faster — with governance built in from day one.

Prompt Tip of the Day
This simple, unassuming prompt is your universal “clarity filter.” It works for anything (planning a trip, writing an email, debugging code, picking a tool) because it forces the model to find the missing info that actually changes the answer.
Before you start, ask me up to 7 targeted questions that would materially improve the answer. If any info is missing and you must proceed, state your assumptions clearly.
Let us know if you found this helpful!
Treats to Try
*Asterisk = from our partners (only the first one!). Advertise to 600K readers here!

- Every Guru answer is cited, permission-aware, and logged—so your AI is finally accountable.*
- Microsoft TRELLIS.2 turns a text prompt or a single image into a downloadable 3D object you can drop into a game/AR scene—like “a ceramic frog mug” → a textured 3D model.
- I‑Scene lets you generate interactive 3D scenes that generalize to unseen layouts by learning spatial relations from a pre‑trained 3D “instance” model (code).
- DataLane maps every U.S. local business with verified owner info and accurate addresses—companies using it see connect rates jump from 30% to 80%+ (raised $22.5M).
- RenderCV turns a YAML file into a PDF resume with multiple output formats—write your CV / resume once in plain text, get professionally formatted PDFs with different themes instantly (free, open source; docs to get started).
- MiMo-V2-Flash turns your text descriptions into working HTML webpages and writes code through Claude Code/Cursor/Cline (ranks #1 among open-source models on SWE-bench at 73.4%)—free trial, then $0.1/M input, $0.3/M output tokens.
Around the Horn
- Waymo suspended its robotaxi service in San Francisco on Saturday night after a massive blackout caused by a fire at a PG&E substation left many of its vehicles stalled on city streets; theories as to why Waymo stopped included traffic lights being down, and/or cell service interruption or loss of traffic data.
- Related: Brad Reed writes that Tesla Robotaxis crashed 8 times in Austin since July and are involved in a crash every 40K miles; about 12.5 times more frequently than human drivers (who crash once every 500,000 miles).
- Thinking out loud… Despite Tesla's higher crash rate today, the company's vehicles could be more reliable longer term than Waym’s fleet if they’re not as reliant on the grid / existing traffic ecosystem (not 100% sure about that either TBH), at least in rural / non-urban environments. It’d be interesting to ask Waymo about this!
- METR found Claude Opus 4.5 has a 50%-time horizon of 4 hours 49 minutes (highest published to date) meaning it can reliably complete tasks taking human professionals nearly 5 hours.
- Adobe got hit with a proposed class action alleging it used pirated books to train SlimLM models.
- Sam Altman’s Worldcoin project now verifies you're a real human on Tinder and confirms your age privately, so you can match with actual people instead of bots or fake profiles.
- Schools started signing deals for ChatGPT and Copilot as students embraced AI and districts tried to steer use into approved tools.
- But also… A school locked down after an AI gun-detection alert—then officials learned it was a student’s clarinet.
- UK AISI warned frontier models made dangerous lab work and self-replication tests easier for novices in recent evals; meanwhile, Britain’s revolving door to U.S. tech accelerated as AI firms loaded up on policy talent.

FROM OUR PARTNERS
Give your hands a break

Ideas move fast; typing slows them down. Wispr Flow flips the script by turning your speech into clean, final-draft writing across email, Slack, and docs. It matches your tone, handles punctuation and lists, and adapts to how you work on Mac, Windows, and iPhone. Start flowing for free today.
Sunday Smarts
- Oracle’s AI boom looked more bubble-ish once its filings showed $248B in off-balance-sheet data-center/cloud lease commitments—huge long-dated obligations that don’t show up as traditional debt.
- Dynamic pricing is quietly getting personalized: one investigation cited 437 Instacart shoppers and found ~3/4 of items showed price variation (up to 23%), which could add up to $1,200/year for some customers. The FTC has since probed Instacart’s AI pricing tool.
- Roundtable argued that language models only feel human on the surface (they’re built on totally different constraints and algorithms), and that scaling will make them less human-like—so we should measure “humanness” by process, not vibes.
- Valmi argued agent builders should charge based on measurable outcomes (tickets resolved, hires made) rather than “how many reasoning steps,” and it estimated a 30% support throughput boost could add ~$20–30M of enterprise value for a $100M company.
- Roon (of OpenAI) argued the primary AI criticism is that it's fake and doesn't work, pointing to viral meltdowns declaring scaling over after GPT-5's launch; however, he countered that GPT-5-pro is producing frontier theoretical physics research, scientists are applying AI to black hole physics and optimization theory, and tiny teams are producing previously impossible amounts of work with AI as a factor of production.
A Cat’s Commentary

