


Hi there!
Heads up: Looks like an earlier version of this email included a busted link to Databricks in it. We’ve fixed it for you; click here to see the page you were trying to reach!
Now, back to your (ir)regularly scheduled newsletter!
So, Linus Ekenstram just shared this Dutch McDonalds commercial that is 100% AI:
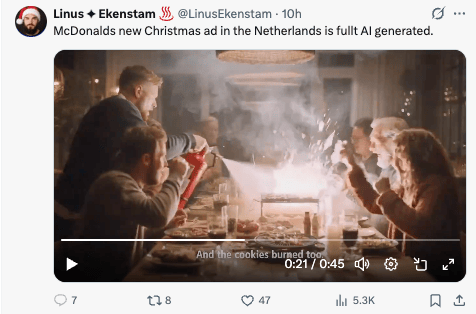
Now compare that commercial to Coca Cola’s “holidays are coming” series, and you can see the two are going after totally different vibes. Coke’s targeting nostalgia, and McDonald’s is targeting the lolz.
Well, turns out the lolz backfired… Three days later? McDonald's pulled it. They called it “an important learning“ as they explore AI's “effective use.“
Why? Because viewers called it “creepy,“ “poorly edited,“ and “the most god-awful ad I've seen this year.“ The uncanny-looking characters and choppy stitched-together clips (most genAI clips are only 6-10 seconds, so a 45-second ad needs tons of edits) didn't help. Comments also flagged concerns about job displacement: “No actors, no camera team...welcome to the future of filmmaking. And it sucks.“ “
Meanwhile, Coca-Cola's second AI-generated Christmas ad earned a 61% positive sentiment rating. Turns out, not all AI holiday ads are created equal… some hit nostalgia, others just hit different.
Here’s what happened in AI today:
- NVIDIA released Nemotron 3 Nano amidst a wave of open releases.
- Zoom launched AI Companion 3.0 with new workflow and search features.
- Allen AI released OLMo 3.1, the strongest fully open reasoning model.
- Starcloud created the first ever AI model trained in orbit.

NVIDIA Just Dropped the Most Efficient Open AI Model… And Gave Away the Entire Recipe

NEWS BRIEF: NVIDIA’s Nemotron 3 Nano, Explained
While everyone's been watching Chinese labs dominate open source AI, NVIDIA quietly built something different: not the biggest model, but potentially the smartest architecture.
On Monday, NVIDIA released Nemotron 3 Nano, a 30-billion parameter model that's rewriting the efficiency playbook for open AI (not to be confused with OpenAI, lol). The headline number: up to 3.3x higher throughput than comparable open models. But the real story is how they got there… and what they're giving away.
The hybrid architecture breakthrough: Nemotron 3 Nano combines standard transformers with state space models in a mixture-of-experts design, activating only 3 billion parameters per token while maintaining access to the full 30 billion when needed. This is basically a fundamental rethink of how to build production AI systems.
The results show up where it matters:
- Bronze-medal performance on International Mathematical Olympiad benchmark.
- 1 million token context windows.
- Strong performance on agentic tasks.
- Generates roughly 377 tokens per second (per Artificial Analysis benchmarks).
What makes this release different: NVIDIA released the complete training recipe:
- 3 trillion tokens of pretraining data.
- Post-training datasets.
- Reinforcement learning environments (NeMo Gym and NeMo RL).
- Infrastructure code.
As Casper Hansen put it: “NVIDIA is fast becoming open-source kings.”
If you want to run this yourself, you need:
- A computer with at least 25GB of RAM.
- This model, which you can run with LM Studio.
This matters because the open source AI landscape has shifted dramatically. Nathan Lambert's 2025 tier list shows Chinese labs (DeepSeek, Qwen, Kimi) now define the frontier. No US company appears in the top tier. NVIDIA's response was to compete on efficiency and openness.
Today's open source flood: NVIDIA wasn't alone. Monday brought a coordinated wave of open releases:
- OLMo 3.1 from Allen AI extended their reinforcement learning runs by 21 days, producing the strongest fully open reasoning model—gaining +5 points on AIME math problems and +20 on instruction-following benchmarks. The complete model flow includes Think 32B for reasoning and Instruct 32B for chat / agents.
- Bolmo introduces byte-level tokenization; processing raw bytes instead of subword tokens for better code, math notation, and multilingual text handling. Available in 7B and 1B sizes, able to run locally on something like LM Studio
- DistillKit from Arcee AI provides open source tools for model distillation; compressing larger models into smaller, faster versions for edge deployment.
P.S: You can see other new models that are popular to run on your own computer here; just follow the star and download count.
The strategic bet: As AI agents become more autonomous and token volumes explode, inference efficiency (running AI) matters more than training scale. NVIDIA is positioning Nemotron as the architecture for production agentic systems, where generating hundreds of thousands of tokens per task makes cost-per-token the key metric.
Super and Ultra versions of Nemotron 3 are coming within months. If those extend the efficiency gains to larger-scale reasoning, NVIDIA may have found a path to frontier performance without frontier budgets.
All models are available on Hugging Face with local deployment options.
P.P.S: Google's Gemma 4 (or something similar) is expected this week, too. Gemma is Google’s open model that you can run locally; 3n is their small one, which you can technically run on your phone via something like Locally AI or for Android, Google’s own AI Edge Gallery.

FROM OUR PARTNERS
Agents that don’t suck

Are your agents working? Most agents never reach production.
Agent Bricks helps you build high-quality agents grounded in your data. We mean “high-quality” in the practical sense: accurate, reliable and built for your workflows.
Generic benchmarks don’t cut it. Agent Bricks measures performance on the tasks that matter to your business.
Evaluate agents automatically, and keep improving accuracy with human feedback. With research-backed techniques for building, evaluating and optimizing, you can turn your business data into production agents faster — with governance built in from day one.

Prompt Tip of the Day
Brian Roemmele just open-sourced a Grok prompt that bypasses AI's consensus bias. His “Deep Truth Mode” uses an 8-step forensic protocol that simultaneously steel-mans the mainstream position, the suppressed position, AND hybrid hypotheses—then red-teams all three to see what survives.
It only uses primary sources (patents, leaked documents, raw datasets, sworn testimony) and explicitly rejects fact-checker articles as evidence. The output includes a probability distribution on which hypothesis has the strongest explanatory power and flags any evidence of active suppression.
TL;DR: It's designed to make AI question everything; including its own training data. And Brian says CS classes are now using it to teach language model limitations; one group even turned it into a system prompt for an open-source model with “better benchmarks across all testing.” Students say it makes Grok their best-performing model. Worth testing on controversial topics where you suspect the “official story” might be incomplete. Here’s a google docs version you can copy.
He has two more prompts for this here (which forces primary-source reasoning in Grok) and and here (a training algorithm rewarding pre-1970 primary data) as well.
Treats to Try
*Asterisk = from our partners (only the first one!). Advertise to 600K readers here!

- *Dell Pro Max with GB10 runs open models like NVIDIA Nemotron models entirely locally. With 128GB unified memory and 4TB storage, it handles workloads that usually require sending everything to OpenAI or Anthropic—except your data never leaves your network. Keep your data local.
- Zoom launched AI Companion 3.0 with a new web interface, personal workflows that automatically execute follow-up tasks like daily reflection reports, agentic retrieval across meetings and connected apps (Google Drive, OneDrive), and agentic writing mode that drafts documents based on meeting context.
- Manus 1.6 now builds mobile apps from your description, lets you edit images with point-and-click precision (change colors, modify text, combine images), and runs on a new Max agent that completes complex tasks like financial modeling or invoice-parsing web apps in one shot with 19% higher satisfaction.
- Mocha builds working web apps from your description—handling database, authentication, payments, and deployment automatically while remembering your entire project across sessions.
- ChatGPT now lets you branch chats to take them in different directions on both iOS and Android.
Around the Horn
- Sam Altman’s World project launched its new app version with end-to-end encrypted chat and a Venmo-like flow for sending / requesting crypto.
- Amazon Prime Video pulled its AI recaps after a Fallout recap misdated a flashback as the 1950s instead of 2077.
- Purdue will require all undergrads to demonstrate basic AI competency starting in 2026 as part of its broader AI strategy.
- Microsoft Copilot started showing up on LG TVs via a webOS update, and owners reported the app couldn’t be removed.
- Speaking of data centers in space… Starcloud trained the first AI model in orbit using a satellite carrying NVIDIA hardware.

FROM OUR PARTNERS
Ideas move fast; typing slows them down.

Wispr Flow flips the script by turning your speech into clean, final-draft writing across email, Slack, and docs. It matches your tone, handles punctuation and lists, and adapts to how you work on Mac, Windows, and iPhone.
Give your hands a break ➜ start flowing for free today.

Monday Meme

A Cat’s Commentary

