
Kyutai's Pocket TTS is a 100M-parameter text-to-speech model that runs faster than real-time on your CPU. Clone any voice with just 5 seconds of audio—fully local, fully open-source, and no cloud required.

Most AI voice models demand expensive GPUs and cloud APIs to generate speech. Not ideal if you're building a voice assistant or just want to clone your voice without burning through compute credits.
Kyutai just released Pocket TTS, a text-to-speech model so small (100M parameters) it runs faster than real-time on your CPU—no fancy GPU needed. Watch the demo here.
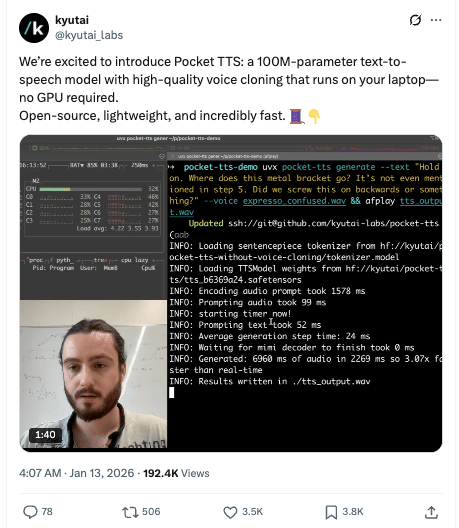
The model delivers high-quality voice cloning using just 5 seconds of audio. Give it 5 seconds of someone's voice, and it'll clone their tone, accent, emotion, and even the room acoustics and microphone quality. Kinda like how your nephew can do a perfect impression of that one annoying TikTok video on repeat, so now you can do it too. Anyone else’s extended family ban the phrase “6 7” after last year’s Thanksgiving?
Once the voice is cloned, it then generates speech in that voice at 6x faster than real-time: all running locally on a standard laptop processor.
The numbers speak for themselves:
The breakthrough comes from Continuous Audio Language Models (CALM), a new framework that predicts audio directly instead of converting it to discrete tokens first. This eliminates the computational bottleneck that made previous TTS models GPU-dependent.
Traditional voice AI follows a three-step process:
Each step adds overhead. It’s faster to process, but you lose quality with every cut.
CALM (Continuous Audio Language Models) skips chunking and even tokenization entirely, predicting smooth, uncompressed representations of sound. It's like describing a sunset with infinite color gradients instead of, y’know, 8 crayons.
Why this matters: Voice AI just became accessible to any developer (or even you) with a laptop. Building voice assistants, audiobook narrators, or accessibility tools no longer requires expensive infrastructure (or an expensive ElevenLabs subscription, tho don’t cry for them; they just hit $330M in ARR, which = annualized recurring revenue). This is part of a broader shift toward edge AI that we’ll see get even bigger this year: powerful models getting small enough to run locally while maintaining quality.
What you can do today that was impossible yesterday:
The privacy angle matters most. Until now, voice cloning meant sending audio to someone else's servers. Medical dictation, legal depositions, confidential business communications; all required trusting a third party. Now? Your voice never leaves your machine.
Over the next year, expect more foundation models to follow this pattern: smaller, faster, and designed for devices you already own (led by the new partnership between Apple and Google). Developers can start using Pocket TTS immediately; if you wanna try it yourself, the full technical report includes setup instructions and voice samples.
Grant Harvey is the Lead Writer of The Neuron, where he continues to lead the publication's daily coverage of AI news, tools, and trends.

Don't fall behind on AI. Get the AI trends & tools you need to know. Join 700,000+ professionals from top companies like Microsoft, Apple, Salesforce and more.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.
