


The start of 2026 brought two research papers that challenge core assumptions about how AI models should work, and together, they reveal a shift in how researchers are thinking about the Transformer architecture that powers every major AI system.
First up, on New Year's Eve, DeepSeek released a paper introducing mHC (Manifold-Constrained Hyper-Connections), which solves critical stability problems in neural network training. Days earlier, researcher Zhang Chong published "Attention Is Not What You Need," proposing Grassmann flows as a complete replacement for the attention mechanism that's defined AI since 2017.
Neither paper alone would rewrite the field. But together, they point to something bigger: a growing belief among researchers that the mathematical chaos inside today's AI models (and the thing that makes them so hard to understand and predict) might not even be necessary for them to function.
DeepSeek's stability fix
As AI researcher Rohan Paul explains, DeepSeek's breakthrough addresses a problem with "Hyper-Connections," an architecture introduced by ByteDance in 2024:
- Think of neural networks as processing information through highway lanes.
- Traditional Transformers use one lane.
- Hyper-Connections expanded this to multiple parallel lanes, allowing models to handle more information without extra computational cost.
The problem? Those parallel lanes kept crashing during training. According to Rohan's technical breakdown, signals would either explode to 3,000 times their normal size or fade to nothing, making training unstable and limiting scalability.
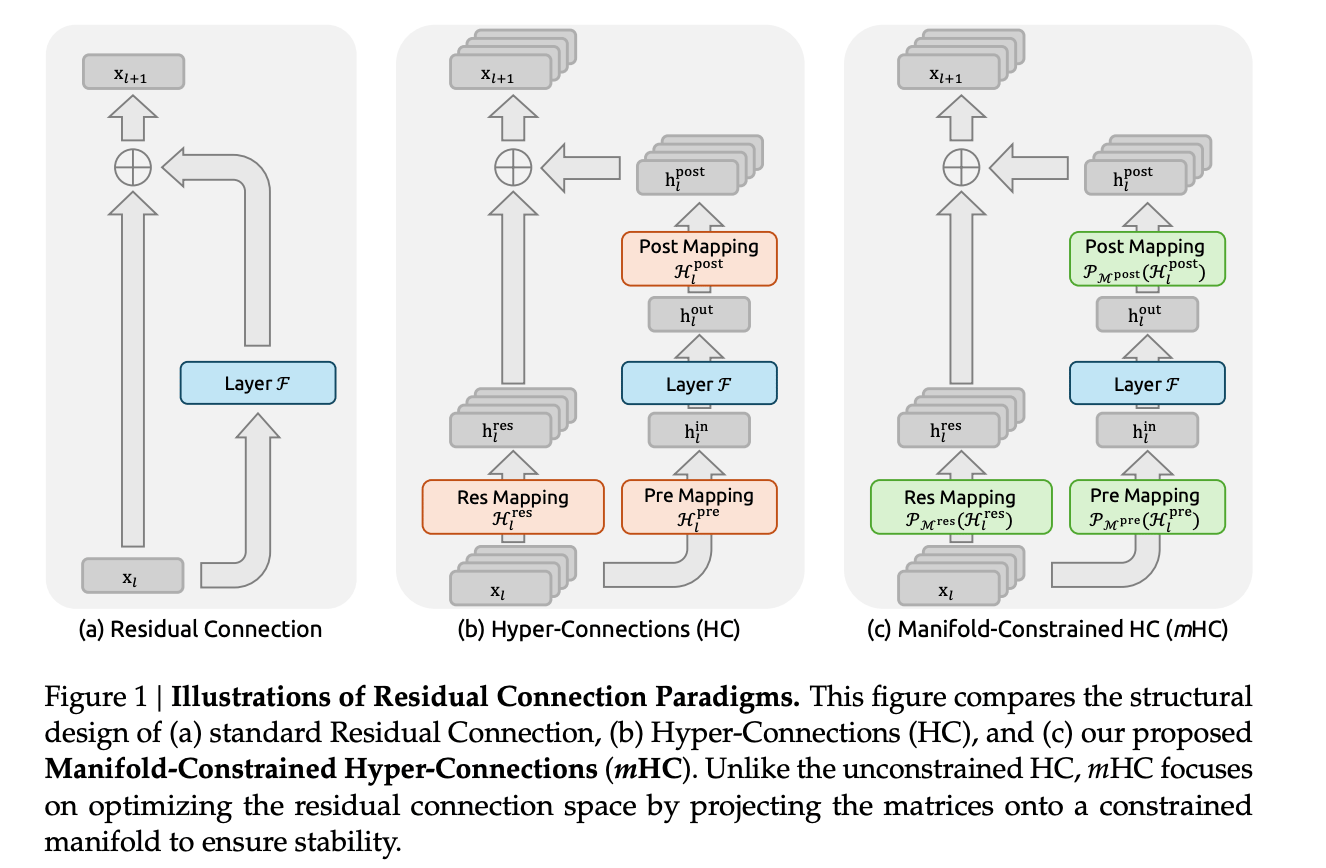
Diagrams comparing mHC, HC, and RC.
DeepSeek's mHC solution adds mathematical "guardrails" called manifold constraints. Instead of letting those information streams run wild, the system forces them to behave like controlled averages. Rohan notes this keeps signal amplification stable at around 1.6x instead of spiking to 3,000x.
Real-world results: DeepSeek tested this on models from 3 billion to 27 billion parameters (those are the adjustable numbers the model learns during training; a billion-parameter model is considered mid-sized these days, and GPT-4 is something like 1.7 trillion parameters). The old approach showed loss spikes and training crashes around step 12,000. mHC stayed smooth throughout. Performance improved across all 8 benchmarks tested, with 7.2% gains on complex reasoning and 6.9% on reading comprehension. Custom GPU optimizations kept overhead at just 6.7% despite running four parallel streams instead of one.
Grassmann flows: questioning attention itself
The Grassmann flows paper challenges the assumption that's powered every major AI breakthrough since 2017: that attention mechanisms are necessary for strong language models.
Quick context: attention mechanisms are how AI models figure out which words matter most when understanding a sentence. When you read "The cat sat on the mat because it was tired," attention helps the model know "it" refers to the cat, not the mat. This has been the secret sauce behind ChatGPT, Claude, and every modern AI.
Here's the claim: instead of computing relationships between every token pair (the famous "attention is all you need" approach), researchers propose Grassmann flows instead—a geometry-based alternative that could make transformers faster, more interpretable, and better at long-context reasoning.
Quick vocab: A token is roughly a word or word chunk—"running" might be one token, while "unbelievable" might be split into "un" + "believ" + "able." Transformers are the architecture powering modern AI—think of them as the blueprint that ChatGPT and Claude are built on.
The timing matters. As models push toward million-token context windows (that's roughly 750,000 words, or about 10 full novels), attention's O(N²) scaling becomes a massive bottleneck. Every time you double the sequence length, attention computations quadruple.
Translation: O(N²) scaling means if you go from analyzing 1,000 tokens to 2,000 tokens, the compute needed doesn't just double—it goes up 4x. Go to 4,000 tokens? Now it's 16x the work. This gets expensive fast.
Here's how Grassmann flows work differently:
- Rather than creating an L×L attention matrix showing how every token relates to every other token, the Causal Grassmann layer:
- An L×L attention matrix is a giant table where L = length of your text.
- If you have 1,000 words, you get a 1,000×1,000 grid showing every word's relationship to every other word. That's 1 million connections to calculate.
- Reduces token states linearly (cheaper than full pairwise comparisons), (Token states = the numerical representation of each word at that point in processing)
- Encodes local token pairs as 2D subspaces on a Grassmann manifold using Plücker coordinates (geometric representation instead of learned weights).
Okay, this sounds wild but here's the gist:
- Instead of learning a million arbitrary weights to connect words, this approach represents word relationships as geometric shapes that can be mathematically described.
- Think of it like using actual geometry rules instead of trial-and-error number crunching.
- Fuses these features back into hidden states through gated mixing.
- Hidden states = the evolving understanding of what each word means as it passes through the model.
- Gated mixing = a controlled way of blending information, like adjusting volume knobs to mix audio tracks.
Think of it like this: attention maps every word to every other word in a giant compatibility matrix. Grassmann flows instead represent nearby word relationships as geometric objects, then composes them.
The paper argues attention is "tensor lifting", or mapping hidden vectors (lists of numbers representing each word) into a high-dimensional space where learning happens through gradient descent (how AI learns; imagine a ball rolling down a hill to find the lowest point; the model adjusts its weights to "roll downhill" toward better answers). So tensor lifting means taking those simple lists and projecting them into a way more complex mathematical space where patterns become easier to spot. Gradient descent is how AI learns—imagine rolling a ball down a hill to find the lowest point; the model adjusts its weights to "roll downhill" toward better answers.
Empirical results
The paper tested this on language modeling (Wikitext-2) and reading comprehension (SNLI). A purely Grassmann-based model with 13-18 million parameters achieved results within 10-15% of a Transformer baseline on language modeling. On SNLI, it slightly outperformed the Transformer approach.
More importantly: the complexity of this method scales linearly with text length instead of quadratically. It might be worth explaining how compute scaling works to put this in perspective.
Traditional Transformers (The Problem)
Quadratic explosion: Standard attention requires every token to look at every other token. This creates an L×L attention matrix.
- 1,000 tokens = 1 million connections.
- 2,000 tokens = 4 million connections.
- 10,000 tokens = 100 million connections.
So if you double the context window → you quadruple the compute. This quadratic scaling (technically O(N²), not exponential, but it grows fast enough to feel exponential) makes processing long documents prohibitively expensive (which partially explains why Google can offer 1M context windows in Gemini and AI Studio, and OpenAI and Anthropic can't unless they charge you full API credits for it).
Grassmann Flows as a Solution
As explained above, the paper achieves O(N) complexity instead:
New way (linear):
- 1K tokens: 1K operations.
- 10K tokens: 10K operations (10× more compute).
- 100K tokens: 100K operations (100× more compute).
The key insight: Rather than having every token attend to every other token (quadratic), they encode local relationships geometrically and fuse them linearly.
So doubling the context only doubles compute, not quadruples it. This makes million-token context windows theoretically feasible where they're currently impossible with standard attention. Meaning no more exponential compute explosion as context windows grow.
So if attention-free architectures can match transformer performance, we unlock models that are faster, more interpretable, and potentially better at reasoning tasks that require tracking long-range dependencies (a long-range dependency is when words far apart in a sentence need to connect, like "The keys that I left on the kitchen counter yesterday morning are in my pocket" where "keys" and "are" are separated by 11 words; this would be huge for the kinda work I do!). And the O(N²) bottleneck disappears.
How the approaches differ... and complement each other
These papers take different approaches to the same underlying problem. Both papers tackle mathematical chaos in Transformers, but they operate at different levels of ambition.
Modern Transformers operate through what researchers call "tensor lifting", which is mapping simple word representations into extremely high-dimensional spaces where learning happens through gradient descent (the process where the model adjusts millions of numerical weights by "rolling downhill" toward better predictions, like a ball finding the lowest point in a landscape). This is powerful but mathematically opaque; after the model transforms data through hundreds of layers in these high-dimensional spaces, there's no way to trace back and explain in simple terms what patterns it actually learned (hence the problems with interpretability, and why we call modern neural nets black boxes; its nigh impossible to reverse engineer them after this process).
As the Grassmann paper argues: "A major source of large-model uninterpretability is that the tensor lifting performed by attention is mathematically non-traceable." After many layers, you can't easily describe what the model learned. The degrees of freedom are too vast.
DeepSeek's mHC doesn't eliminate this. It's a pragmatic fix. It accepts the existing Transformer architecture (attention mechanisms, residual connections, the whole stack) and constrains it with mathematical guardrails to make it stable. The key innovation is forcing those parallel information streams to behave like doubly stochastic matrices (mathematical structures where each row and column of numbers adds up to 1, ensuring the operation stays balanced and can't spiral out of control), which means every mixing operation becomes a controlled weighted average (combining values where the mixing weights add up to 1, keeping results bounded) rather than arbitrary multiplication (where you could multiply by any number—1,000x or 0.001x—causing signals to explode or vanish).
This is engineering: take what works, identify where it breaks, add mathematical guardrails.
The constraints are specifically designed to preserve what's called "identity mapping": ensuring that as information flows through hundreds of layers, it doesn't explode or vanish. As Rohan Paul notes, DeepSeek engineered custom GPU kernels and used techniques like the Sinkhorn-Knopp algorithm to enforce these constraints efficiently. The result: you get the benefits of wider residual streams without the instability.
Grassmann flows is a philosophical overhaul. It doesn't try to fix attention; in fact, it argues attention was the wrong choice from the start. Instead of letting models learn arbitrary pairwise weights between every token, it forces all word relationships to live on a Grassmann manifold, a geometric space where relationships must follow explicit mathematical rules.
For example: word pairs must be represented as 2-dimensional planes in space, and those planes are encoded using a fixed formula called Plücker coordinates, calculated as pairwise determinants like "word1's value × word2's dimension minus word1's dimension × word2's value", and these coordinates must satisfy specific algebraic constraints that prevent arbitrary values, unlike attention weights which can be any number the model learns.
The practical implications differ too. DeepSeek's approach adds 6.7% training time overhead but makes existing architectures more stable and scalable. You could drop mHC into current training pipelines without fundamentally changing how models work. Grassmann flows eliminates the quadratic scaling problem entirely (going from O(N²) to O(N) complexity) but requires rethinking the entire architecture from scratch.
Interestingly, these approaches aren't mutually exclusive. You could imagine a future architecture that uses Grassmann-style geometric constraints for local interactions while using mHC-style stability guarantees for deeper layers. Both papers share the same intuition: that imposing explicit mathematical structure on how information flows makes models more tractable without sacrificing capability.
Why this matters
Training frontier AI models costs tens of millions and takes months. One crash halfway through wastes weeks and millions in compute. DeepSeek's work makes that process more reliable.
In an industry where training costs are a major bottleneck, stability improvements and architectural rethinking aren't flashy. But they're the unglamorous engineering that makes the next generation of AI models possible.
Looking ahead, DeepSeek has a pattern of publishing research before major releases. Founder Liang Wenfeng personally uploaded this paper to arXiv, continuing his habit of sharing technical work ahead of product launches. Last year, DeepSeek released its reasoning model R1 just before Chinese New Year (which starts February 17 this year). Therefore, industry watchers expect a new flagship model soon.
Meanwhile, expect serious scrutiny of Grassmann flows over coming months as researchers test whether it scales to billion-parameter models. Transformers have survived many challengers (Mamba, RWKV, various linear attention variants) but this geometric approach represents genuinely novel thinking.
But the broader trend is more interesting: researchers are increasingly questioning whether the mathematical complexity inside Transformers is a feature or a bug. Could we build models that are simultaneously more capable, more efficient, and more interpretable? Certainly the team at Pathway thinks so, as demonstrated by their Baby Dragon Hatchling architecture. While their work builds on the Transformer and expands it, it fundamentally reconstructs it from the ground up using biological principles.
If DeepSeek is trying to install guardrails on the Transformer, and the Grassmann team is trying to replace the engine entirely, the Baby Dragon Hatchling (BDH) represents a third path: deriving the Transformer architecture from the laws of nature.
Published by researchers at Pathway, the BDH paper argues that the opaque mathematics of modern AI can be replaced by "local graph dynamics", essentially treating the AI not as a matrix multiplication machine, but as a swarm of interacting particles, similar to neurons in a biological brain.
Here is how BDH connects to (and differs from) the other two breakthroughs:
1. Solving Stability
DeepSeek’s mHC paper identified that parallel information streams ("Hyper-Connections") tend to explode or vanish, requiring complex mathematical constraints to stabilize. BDH solves this same problem but through biological emulation.
- DeepSeek's approach: Force the math to behave using "manifold constraints" (making matrices doubly stochastic).
- BDH's approach: Treat the model as a system of n interacting particles. In nature, biological neurons have built-in "inhibitory circuits" and thresholds that prevent signals from exploding.
- The Result: BDH achieves stability naturally. By using "local edge-reweighting" (a fancy term for how synapses strengthen or weaken based on usage), BDH naturally creates a stable, scale-free network without needing the heavy-handed mathematical clamps that DeepSeek employs.
2. Rethinking Attention
The Grassmann Flows paper argues that the quadratic O(N²) attention mechanism is inefficient and mathematically messy. BDH agrees, but rather than abandoning attention for pure geometry, it simplifies attention into Linear Attention.
- The Grassmann Argument: Attention matrices are too expensive and opaque. We should use geometric flows.
- The BDH Solution: Attention is actually just Hebbian Learning ("cells that fire together, wire together").
- How it works: Instead of calculating a massive grid of how every word relates to every other word (the standard Transformer way), BDH uses a "linear attention" mechanism in a high-dimensional space. This reduces the complexity from quadratic to linear—meaning the model can theoretically handle infinitely long contexts without the computational explosion that plagues current LLMs.
3. The Unique Breakthrough: "Monosemanticity"
Where BDH truly diverges from both DeepSeek and Grassmann is in interpretability.
Current Transformers are "black boxes"; we know they work, but we don't know where the concept of "France" or "multiplication" lives inside the model. Because BDH simulates physical particles and synapses, its internal components are remarkably distinct (or "sparse").
So the researchers found "monosemantic synapses", or single connections in the model that activate only for specific concepts.
- Example: They identified a specific synapse that only fires when the text mentions a currency (like "Euro" or "Dollar") or a country.
- Why this matters: In a standard Transformer, the concept of "currency" is smeared across billions of parameters. In BDH, you can point to a specific digital synapse and say, "That is where the model understands money."
Anyway, that just a handful of interesting paths forward. If you are building applications today, DeepSeek’s stability fixes are the most immediately applicable. But if you are looking at where the puck is going, the linear scaling and interpretability of architectures like BDH and Grassmann suggest that the era of the opaque, quadratic "Black Box" Transformer may be coming to an end. Not anytime soon, but at some point? It's very possible...
