


The dream of AI that truly learns and adapts (without forgetting what it already knows) has long eluded researchers. But in the final weeks of 2025 and early January 2026, four major papers dropped that each tackle different pieces of this puzzle. Together, they paint a picture of what continual learning might actually look like.
Let's break down each approach, then connect the dots.
- The Core Problem: Learning Is Broken in Two Different Ways
- Paper 1: EAFT — Entropy-Adaptive Fine-Tuning
- Paper 2: TTT-E2E — Test-Time Training End-to-End
- Paper 3: DroPE — Dropping Positional Embeddings
- Paper 4: RLMs — Recursive Language Models
- Connecting the Dots: A Unified View
- What This Means for You
- The Road Ahead
The Core Problem: Learning Is Broken in Two Different Ways
Before diving into the solutions, we need to understand why current approaches fail.
Supervised Fine-Tuning (SFT) is the standard way to adapt a pretrained model to new tasks. You show it examples, it learns the pattern. Simple. The problem? Catastrophic forgetting. Fine-tune a model on medical data, and it might suddenly forget how to code. The new knowledge overwrites the old.
Reinforcement Learning (RL), on the other hand, preserves existing capabilities better—but it struggles to fundamentally shift the model to new distributions. RL is great for sharpening what a model already knows, but less effective at teaching it genuinely new things.
The four papers we're examining each approach this problem from a different angle:
- EAFT asks: What if we could fine-tune selectively, only updating when the model is genuinely uncertain?
- TTT-E2E asks: What if we compressed context into model weights at test time, like human memory?
- DroPE asks: What if the architectural features that help training are actually hurting generalization?
- RLMs ask: What if we let the model programmatically manage its own context, offloading long prompts to an external environment?
P.S: Those two links we provided are explained excellently by Cameron Wolfe and his Deep Learning Focus Substack. Check him out!
Paper 1: EAFT — Entropy-Adaptive Fine-Tuning
The Core Insight
The EAFT team from Beijing University of Posts and Telecommunications made a crucial discovery: catastrophic forgetting isn't caused by learning new things. It's caused by overwriting things the model was already confident about.
They call these "Confident Conflicts"—cases where:
- The model has low entropy (it's highly confident in its prediction).
- But the training label strongly disagrees with that prediction.
When standard SFT encounters a Confident Conflict, it applies large gradients to force the model to change its answer. These destructive gradient updates don't just teach the new information—they bulldoze existing knowledge in the process.
The Distributional Gap Between SFT and RL
Here's why RL preserves capabilities better: RL training data comes from the model itself. When you do on-policy RL, the model generates responses, gets feedback, and adjusts. This naturally aligns with the model's internal beliefs.
SFT data, by contrast, comes from external supervision. The model has no say in what it's being taught. This mismatch creates friction, and that friction manifests as Confident Conflicts.
The EAFT authors visualized this by plotting tokens across two dimensions: probability (how likely the model thinks the ground truth token is) and entropy (how certain the model is about its own prediction). SFT data clusters heavily in the "Confident Conflict" zone—low probability, low entropy. RL data doesn't.
The Solution: Entropy-Based Gating
EAFT introduces a beautifully simple fix: use token-level entropy as a gating mechanism for the training loss.
The standard Cross-Entropy loss treats every prediction error equally. EAFT modifies this:
L_EAFT(θ) = -Σ H̃_t · log P_θ(y_t | x, y_
Where H̃_t is the normalized token-level entropy.
What this means in practice:
High entropy (model is uncertain) → Full learning signal. The model doesn't know the answer, so teach it.Low entropy + conflict (model is confident but wrong) → Suppressed learning signal. The model "thinks" it knows the answer. Forcing a change would be destructive.
This is fundamentally different from approaches that only look at prediction probability. A model might assign low probability to the correct answer for two very different reasons:
It genuinely doesn't know (high entropy—epistemic uncertainty)It's confident in a different answer (low entropy—knowledge conflict)
EAFT distinguishes these cases. Standard probability-based reweighting can't.
Validation: The 15% Pilot Study
To confirm their hypothesis, the researchers ran a pilot study. They simply masked out the loss contribution of the lowest 15% of tokens by entropy and probability—the "Confident Conflict" tokens.
The result? Catastrophic forgetting was significantly mitigated compared to standard SFT. This simple masking experiment confirmed that those specific tokens were the primary driver of capability degradation.
The Math Behind EAFT
The standard Cross-Entropy loss for language modeling is:
L_CE(θ) = -Σ log P_θ(y_t | x, y_
Every token contributes equally, regardless of whether the model is confident or uncertain. EAFT modifies this by weighting each token's contribution by its normalized entropy:
L_EAFT(θ) = -Σ H̃_t · log P_θ(y_t | x, y_
Where H̃_t is computed as:
H_t = -Σ P_θ(v | x, y_H̃_t = H_t / log|V| [normalized to [0,1]]
The beauty of this formulation: it requires no hyperparameters. The entropy of the model's own prediction distribution provides all the gating signal needed. This is in stark contrast to previous approaches that required tuning thresholds or learning separate gating networks.
Why Entropy Beats Probability Weighting
Why Entropy Beats Probability WeightingYou might wonder: why not just weight by the probability of the ground truth token? Several prior works have tried this. The problem is that low probability can mean two very different things:
Epistemic uncertainty: The model genuinely doesn't know. Distribution is spread across many tokens. High entropy.Knowledge conflict: The model is confident in a wrong answer. Distribution is peaked, just not on the target. Low entropy.
Case 1 represents a learning opportunity—the model should update. Case 2 represents a Confident Conflict—updating would be destructive.
Probability alone can't distinguish these cases. A token with 5% probability could be:
Part of a nearly uniform distribution (20 tokens each with ~5%) → High entropy → Should learnThe second-most-likely token behind a 90% candidate → Low entropy → Should not learn
EAFT's entropy gating catches this distinction. The researchers validated this with ablation studies comparing entropy weighting, probability weighting, and combined approaches. Pure entropy weighting consistently outperformed probability-based alternatives.
Experimental Results
Experimental ResultsEAFT was tested across three domains representing different types of learning:
Math (reasoning-intensive): AIME24, AIME25, GSM8K—tests logical reasoning capabilitiesMedical (knowledge-intensive): MedMCQA, MedQA, PubMedQA—tests factual knowledge retentionAgent/Tool-Use (format-intensive): BFCL v3—tests structured output formatting
Across Qwen and GLM model families (4B to 32B parameters), the pattern held:
Downstream performance: EAFT matches standard SFT on the target domainGeneral capability preservation: EAFT significantly outperforms SFT
Notice how SFT on medical data improved knowledge benchmarks but devastated code performance (62.3 → 54.8). EAFT preserved code capabilities (62.3 → 61.1) while achieving nearly identical medical performance.
For the larger Qwen3-32B-Thinking model, the gap was even more dramatic. Standard SFT caused general benchmark scores to drop from 86.1 to 81.3 (a 4.8-point decline). EAFT maintained scores at 85.1—preserving 78% of the capability that SFT destroyed.
Scaling Behavior
Scaling BehaviorAn important finding: EAFT's benefits scale with model size. Smaller models (4B) showed modest but consistent improvements. Larger models (32B) showed larger absolute gains. This suggests that as models become more capable, the risk of Confident Conflicts increases—and so does the value of entropy-adaptive training.
Why This Matters
Why This MattersEAFT suggests that the path to continual learning requires distribution-aware training with selective, uncertainty-aware updates. You can't just show a model data and expect it to learn without damage. You need to respect what it already knows.
The method has already been integrated into LLaMA-Factory (via the use_eaft_loss parameter) and ms-swift, making it immediately accessible to practitioners.
Paper 2: TTT-E2E — Test-Time Training End-to-End
Paper 2: TTT-E2E — Test-Time Training End-to-EndPaper Link | NVIDIA Blog | Code
The Core Insight
The Core InsightTTT-E2E starts from a provocative observation: LLM memory and human memory work fundamentally differently.
Humans are remarkably good at improving with more "context" in the form of life experience. You don't remember every word from your first machine learning lecture, but the intuition you learned still helps you years later. Your brain compressed that experience into something useful, preserving the important parts while letting go of details.
Transformers with full attention do the opposite. They're designed for nearly lossless recall—caching and comparing every token's keys and values. This is expensive: the cost per token grows linearly with context length. Processing the 10-millionth token takes a million times longer than processing the 10th.
Modern approximations (sliding-window attention, Mamba, Gated DeltaNet) have constant cost per token, but they lose important information that would help predict the future. You can see this clearly in the loss curves: as context grows, these methods fall further and further behind full attention.
The Solution: Compress Context Into Weights
The Solution: Compress Context Into WeightsWhat if we designed a method with constant cost per token that could still remember the important, predictive information in long context?
The key mechanism is compression—like the human brain does. We know that training with next-token prediction compresses data into model weights. So what if we just continued training the model at test time on the given context?
This is Test-Time Training (TTT). But the naive approach doesn't work well. The crucial addition in TTT-E2E is meta-learning: at training time, you prepare the model's initialization specifically for TTT. This makes the method end-to-end in two ways:
The inner loop directly optimizes next-token prediction lossThe outer loop directly optimizes the final loss after TTT
The Architecture
The ArchitectureTTT-E2E uses a hybrid architecture combining:
Full attention for processing chunks of contextTTT layers that compress information across chunks
The model processes context in chunks of size C. Within each chunk, standard self-attention operates normally. But the TTT layers maintain a compressed state that carries information across chunks.
At each chunk boundary:
The TTT layer takes a gradient step on the chunk using next-token prediction lossThis step updates the TTT layer's internal weightsThe updated weights carry forward to the next chunk
This creates a recurrent structure at the chunk level while maintaining the parallel processing benefits of attention within chunks. The compressed state is not a hidden vector (like in RNNs) but the layer's weight matrices themselves.
Meta-Learning for Better Initialization
Meta-Learning for Better InitializationThe naive version of TTT—just train on the context and hope for the best—doesn't work well. The key innovation in TTT-E2E is meta-learning the initialization.
During pre-training:
Sample a long sequence SInitialize the model at state θ₀Process the first portion S₁ with TTT → produces state θ₁Evaluate loss on the second portion S₂ using θ₁Backpropagate through the TTT steps to update θ₀
This is "learning to learn"—the model learns an initialization that, after TTT adaptation, performs well on held-out portions of the sequence. The meta-learning explicitly optimizes for the ability to compress context usefully.
The Results Are Striking
The Results Are StrikingTTT-E2E was tested on 3B parameter models trained with 164B tokens, scaling context from 128K to 2M tokens.
Loss scaling: While other methods produce worse results in longer context, TTT-E2E maintains the same advantage over full attention regardless of context length. It actually turns the worst-performing method (gray line in their figures) into the best (light green) at 128K context.
Notice two things: First, TTT-E2E beats full attention at every context length. Second, while sliding window and Mamba get progressively worse as context grows (the number increases), TTT-E2E continues improving (the number decreases).
Latency scaling: Like RNNs, TTT-E2E has constant inference latency regardless of context length:
2.7x faster than full attention at 128K context35x faster than full attention at 2M context
The crossover point where TTT-E2E becomes faster than full attention is around 8K tokens. Below that, full attention is faster due to lower overhead. Above that, TTT-E2E's constant-time scaling dominates.
This is the holy grail for long-context work: scale well in both loss and latency. Every other method had to sacrifice one for the other.
What About RAG?
What About RAG?The authors make a compelling analogy: TTT is like updating the human brain, while RAG is like using a notepad. The notepad will continue to be practical for details (like a grocery list), but human productivity is mostly determined by their brains, not their notepads.
Similarly, the productivity of an AI agent is mostly determined by how well it compresses context into predictive, intuitive information—not by how well it retrieves from external storage.
What About Catastrophic Forgetting?
What About Catastrophic Forgetting? When we asked author Karan Dalal about "catastrophic forgetting" on X, he said:
"Two simple strategies:Update only a subset of parameters at test-time. For our experiments, only the SwiGLUs in the final quarter of the network.Leave a “safe” SwiGLU untouched as a stable store of pre-trained knowledge.
There are surely more effective designs here – we didn’t explore this space deeply. But one thing I do feel strongly about is that meta-learning (i.e., learning how to do test-time training) is critical."
Current Limitations
Current LimitationsTTT-E2E's meta-learning phase requires gradients of gradients, and FlashAttention's standard API doesn't support this. The current implementation is 3.4x slower than standard pre-training for short context (8K). This could be fixed with custom attention kernels or by initializing from a standard Transformer pre-trained without TTT.
Why This Matters
Why This MattersTTT-E2E suggests that the solution to long context isn't just architectural tricks—it's fundamentally rethinking what memory means for language models. Instead of trying to maintain lossless access to everything, compress the context into something useful and carry that forward in the weights.
This is how humans work. Maybe it's how AI should work too.
Paper 3: DroPE — Dropping Positional Embeddings
Paper 3: DroPE — Dropping Positional EmbeddingsPaper Link | Sakana AI Blog | Code
The Core Insight
The Core InsightSakana AI's DroPE challenges a fundamental assumption in transformer architecture: that positional embeddings (PEs) are a permanent necessity.
The standard choice for modern LLMs is RoPE (Rotary Positional Embeddings). RoPE is fantastic for training—it bakes in a strong, learnable sense of order. But when you push sequences beyond what the model saw during training, RoPE becomes the main culprit for failure.
Why? RoPE rotations are position-dependent. At unseen sequence lengths, those rotations move out of distribution. The attention heads see scores they've never encountered in training, and performance collapses.
The Training Benefits of PEs
The Training Benefits of PEsBefore explaining how to remove PEs, the authors first establish why they help.
Transformers without positional embeddings (NoPE transformers) are notoriously unstable to train. The reason, the DroPE team discovered, comes down to attention uniformity.
At initialization, all token embeddings are similar (drawn from a distribution with small variance). This causes attention to be nearly uniform—every token attends roughly equally to every other token. Uniform attention means uniform mixing, which means the tokens stay similar, which means attention stays uniform. It's a self-reinforcing cycle.
The Mathematical Story:
Without positional information, attention scores at initialization are approximately:
A_ij ≈ softmax(q_i · k_j^T / √d) ≈ 1/n for all j
Because all embeddings are similar, all dot products are similar, so softmax produces nearly uniform weights. This creates a "smoothing" effect that prevents the model from learning to distinguish positions.
RoPE breaks this cycle by injecting position-dependent rotations:
q_i → R_i · q_ik_j → R_j · k_j
Where R_i is a rotation matrix determined by position i. This ensures that even at initialization, tokens at different positions have different effective query/key representations.
The authors proved theoretically and demonstrated empirically that RoPE models have higher gradient norms at initialization, allowing attention heads to become diagonal or off-diagonal much faster. Since these specialized attention patterns are critical for language modeling, this explains why RoPE models train better.
The Extrapolation Cost of PEs
The Extrapolation Cost of PEsThe problem emerges at test time. Popular "RoPE-scaling" tricks (PI, NTK-aware scaling, YaRN) try to fix length extrapolation by compressing low frequencies to keep phases in range.
This preserves perplexity but quietly shifts semantic heads—the ones that match content across large distances. The result: the model behaves as if the context were effectively cropped to the original training length. You get near-constant perplexity with poor long-range retrieval—exactly the opposite of what long-context tasks need.
Why Scaling Tricks Fail:
The core issue is that RoPE's rotation frequencies are learned relative to training sequence lengths. When you scale positions to fit longer sequences into the same frequency range, you're changing the relative distances that attention patterns encode.
Consider two tokens that were 1000 positions apart during training. After scaling to fit 2x longer context, they might appear to be 500 positions apart to the attention mechanism. This preserves perplexity (local predictions still work) but breaks long-range dependencies (the model can't correctly reason about true distances).
The authors demonstrated this with a "crop baseline": a model that simply ignores tokens beyond its training length. YaRN's needle-in-a-haystack performance matched the crop baseline. The scaling trick preserved perplexity by essentially pretending the extra context didn't exist.
The Solution: Drop PEs After Training
The Solution: Drop PEs After TrainingDroPE's insight is radical: treat positional embeddings as a temporary training scaffold.
The recipe:
Train with RoPE (for stability and fast convergence)Remove positional embeddings entirelyRun a short recalibration phase on the original pretraining data
The recalibration phase is remarkably cheap. For SmolLM models (360M and 1.7B parameters), DroPE recovered 95% of base performance after less than 5B tokens—only 0.8% of the original pretraining budget. Full recovery required 30-120B tokens depending on the model.
For Llama2-7B (pretrained on 4 trillion tokens), recalibration required only 20B tokens—0.5% of the original budget.
Why Recalibration Works
Why Recalibration WorksThe key insight is that RoPE models already learn implicit positional information through causal attention patterns. The causal mask (each token can only attend to previous tokens) provides a strong position signal. RoPE adds explicit position information on top of this.
During recalibration, the model learns to rely more heavily on:
Causal attention patterns: The triangle structure of causal attentionContent-based positioning: Semantic cues that indicate orderRelative patterns in the data: Grammatical and structural regularities
The authors verified this by analyzing attention patterns before and after DroPE. After recalibration, models showed sharper, more localized attention—attending precisely to relevant tokens rather than broadly over position-similar regions.
Experimental Results
Experimental ResultsNeedle-in-a-haystack at 2x training context:DroPE models substantially outperformed both RoPE-scaling methods and alternative PE schemes. The gap was most pronounced on multi-key tasks, where the model must track several different keys in long context.
Attention analysis showed why: DroPE concentrates attention tightly around relevant tokens. The authors measured:
82% peak attention on the needle token72% of attention mass within ±1 token of the needleOnly 9% of attention "bleeding" outside ±4 tokens
RoPE and YaRN showed much wider, more diffuse attention patterns.
LongBench performance:On challenging long-context tasks (some 80x longer than SmolLM's 2048-token training window), DroPE improved the base model's average score by over 10x.
Why This Matters
Why This MattersDroPE suggests that architectural choices optimized for training may actively harm generalization. The features that make learning fast and stable can become constraints that prevent flexible deployment.
The practical implication: you can take existing models, remove their positional embeddings with minimal recalibration, and get dramatically better length generalization. For Llama2-7B, this costs 0.5% of pretraining compute. That's a remarkable trade-off.
Paper 4: RLMs — Recursive Language Models
Paper 4: RLMs — Recursive Language ModelsThe Core Insight
The Core InsightThe MIT team behind RLMs takes a completely different approach: instead of improving how models handle long context internally, offload the context to an external environment.
The key insight comes from out-of-core algorithms in systems programming. Data-processing systems with small, fast main memory can process far larger datasets by cleverly managing how data is fetched into memory. Why can't LLMs do the same?
Current approaches like context condensation (repeatedly summarizing once context exceeds a threshold) presume some details can safely be forgotten. But many tasks require dense access to many parts of the prompt. Summarization loses critical information.
The Solution: Treat Prompts as Environment Variables
The Solution: Treat Prompts as Environment VariablesRLMs expose the same external interface as a standard LLM: they accept a string prompt and produce a string response. But internally, they work very differently.
Given a prompt P:
Initialize a Python REPL environmentSet P as the value of a variable in that environmentTell the LLM the context exists and how long it isLet the LLM write code to peek into, decompose, and recursively call itself over snippets of P
The crucial innovation: by treating the prompt as an object in the external environment, RLMs can handle inputs far beyond the context window of the underlying LLM. Prior recursive decomposition approaches couldn't do this—they still needed to fit the full input into the neural network at some point.
The REPL Environment
The REPL EnvironmentThe RLM environment provides several capabilities:
Context access functions:
get_context_length()→ Returns the total token countpeek(start, end)→ Returns a substring of the contextsearch(pattern)→ Returns positions matching a regex pattern
Recursive invocation:
call_llm(prompt)→ Makes a recursive call with a new (smaller) promptResults are stored in REPL variables for later use
Output functions:
set_answer(response)→ Marks the final answerprint_intermediate(text)→ Logs intermediate reasoning
The LLM sees a system prompt explaining these capabilities, then receives information about the context (length, first few hundred characters as a preview) without the full context loaded into its context window.
Scaling With Task Complexity
Scaling With Task ComplexityThe RLM authors make an important point: effective context window depends on task complexity, not just token count.
They categorized tasks by "information density"—how much of the prompt you need to process:
S-NIAH (constant complexity): Single needle, regardless of input size. Find one piece of information.BrowseComp+ (multi-hop): Answer requires piecing together several documents. Follow chains of references.OOLONG (linear complexity): Must examine/transform nearly all entries. Process each item once.OOLONG-Pairs (quadratic complexity): Must aggregate pairs of entries. Process all N² pairs.CodeQA (repository understanding): Reason over fixed number of files. Understand code structure.
As complexity increases, base LLM performance degrades much faster with length. RLMs show dramatically slower degradation because they can programmatically manage which parts of the context to examine.
Emergent Strategies
Emergent StrategiesWithout explicit training, RLMs developed interesting strategies. The researchers analyzed thousands of RLM trajectories and identified recurring patterns:
Filtering via code: Use regex queries or keyword searches based on model priors to narrow the search space before invoking sub-LMs. If searching for information about "Project Apollo," first search("Apollo") to find relevant sections.
Chunking + recursion: Break context into chunks, query a sub-LM per chunk, aggregate results. For a 10M token document, divide into 1000 10K-token chunks, process each independently, combine findings.
Answer verification: Use sub-LM calls with small contexts to verify answers found in long contexts (avoiding context rot). If an answer is found in chunk #847, extract just that section and verify in isolation.
Variable passing: Build up unbounded outputs by stitching sub-LM results through REPL variables. Store intermediate results as result_1, result_2, etc., then combine them in a final synthesis step.
Model-Specific Behaviors
Model-Specific BehaviorsDifferent models showed different styles when operating as RLMs:
GPT-5 was conservative with sub-calls, building answers iteratively. It typically made 10-50 sub-calls per task, carefully planning each one. GPT-5 showed strong "look before you leap" behavior—analyzing available information before making recursive calls.
Qwen3-Coder was liberal, sometimes making hundreds or thousands of sub-calls per task. It preferred exhaustive exploration over selective probing. While this was more expensive per task, it achieved higher accuracy on tasks requiring comprehensive coverage.
Claude 3.5 showed intermediate behavior—more sub-calls than GPT-5 but more structured than Qwen3-Coder. It frequently used the search function to identify promising regions before peeking into them.
These differences emerged without any RLM-specific training—they reflect the underlying models' reasoning preferences when given programmatic tools.
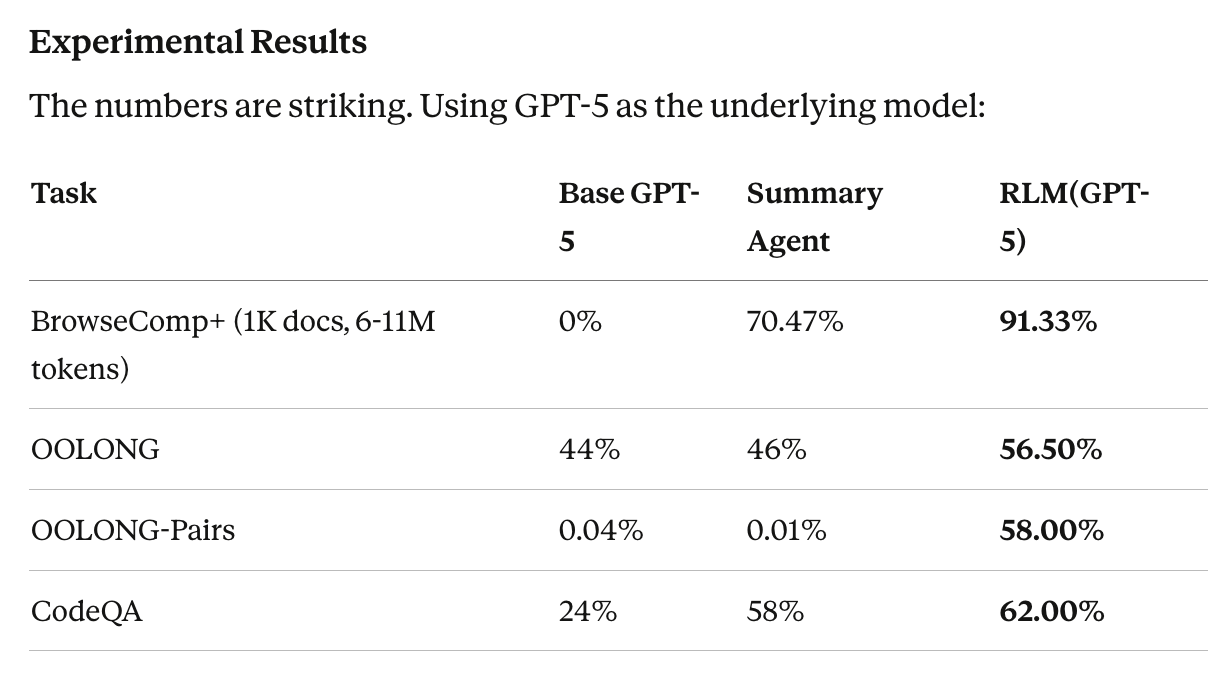
On BrowseComp+ (1000 documents, 6-11 million tokens), the base model scores 0%—it can't fit the input in context. The RLM scores 91.33%.
On OOLONG-Pairs (quadratic complexity), the base model manages 0.04% F1. The RLM achieves 58.00% F1. That's not a percentage-point improvement—it's a qualitative leap from "doesn't work" to "works."
Cost Analysis
Cost AnalysisRLMs aren't just more capable—they can be cheaper. The median RLM run with GPT-5 was cheaper than the median base model run (when the task fits in context at all).
Compared to summarization baselines that ingest the entire input, RLMs are up to 3x cheaper while maintaining stronger performance. The model selectively views context rather than processing everything.
The variance is high—some RLM trajectories are much longer than others—but at the 50th percentile, costs are comparable or lower.
Emergent Behaviors
Emergent BehaviorsWithout explicit training, RLMs developed interesting strategies:
Filtering via code: Use regex queries or keyword searches based on model priors to narrow the search space before invoking sub-LMs.
Chunking + recursion: Break context into chunks, query a sub-LM per chunk, aggregate results.
Answer verification: Use sub-LM calls with small contexts to verify answers found in long contexts (avoiding context rot).
Variable passing: Build up unbounded outputs by stitching sub-LM results through REPL variables.
Different models showed different styles. GPT-5 was conservative with sub-calls, building answers iteratively. Qwen3-Coder was liberal, sometimes making thousands of sub-calls per task.
Limitations
LimitationsCurrent RLMs have room for improvement:
Synchronous sub-calls (slow)Max recursion depth of 1 (sub-calls are LMs, not RLMs)No explicit training for RLM behaviorBrittle final answer detection
The authors suggest that training models specifically for RLM use could yield significant improvements—RLM trajectories could be viewed as a form of reasoning that can be learned.
Why This Matters
Why This MattersRLMs represent a paradigm shift: instead of making models that can hold more context, make models that can manage their own context. The prompt isn't input to the neural network—it's part of the environment the model interacts with.
This approach aligns with "The Bitter Lesson": instead of engineering clever solutions, give models the tools to solve problems themselves. RLMs don't summarize context (lossy); they programmatically access what they need (lossless access to arbitrarily long inputs).
Connecting the Dots: A Unified View
Connecting the Dots: A Unified ViewThese four papers attack different aspects of the same fundamental problem. Here's how they relate:
The Underlying Theme: Distribution Mismatch
The Underlying Theme: Distribution MismatchAll four papers address some form of distribution mismatch:
EAFT: Training data distribution (external supervision) vs. model's internal beliefs. When these clash violently, learning is destructive.
TTT-E2E: Training-time context length vs. test-time context length. Models trained on 8K context must somehow handle 2M context.
DroPE: Training-time positional patterns vs. test-time positional patterns. RoPE creates position-dependent representations that don't generalize.
RLMs: Required context window vs. available context window. Tasks may need millions of tokens; models may have thousands.
Each paper proposes a different resolution:
EAFT: Detect and dampen mismatched updatesTTT-E2E: Adapt the model to each new test distributionDroPE: Remove the architectural source of mismatchRLMs: Sidestep the limitation entirely via decomposition
Complementary Solutions
Complementary SolutionsEAFT + TTT-E2E: EAFT prevents forgetting during domain adaptation; TTT-E2E compresses new context into weights. Together, you could adapt to new domains (EAFT) while efficiently processing the massive context those domains require (TTT-E2E).
Consider a medical AI that needs to process patient histories spanning decades. EAFT allows continuous learning of new medical knowledge without forgetting general reasoning. TTT-E2E compresses the patient's history into the model's weights for efficient reasoning.
DroPE + RLMs: DroPE extends the effective context of the base model; RLMs handle inputs beyond even that extended limit. For a 4K-trained model, DroPE might enable 8K-16K effective context; RLMs then handle the 10M+ token regime.
This creates a natural hierarchy: use DroPE for moderate context extension (cheap, no inference overhead), escalate to RLMs for extreme cases (more expensive, but handles arbitrary lengths).
TTT-E2E + RLMs: TTT-E2E compresses context into weights; RLMs manage what context to compress. RLMs could identify the relevant portions of a massive document corpus, then TTT-E2E could compress those portions into the model's weights for efficient reasoning.
Think of RLMs as a "librarian" that finds relevant books, and TTT-E2E as the "reader" that deeply understands them.
EAFT + DroPE: EAFT enables fine-tuning without forgetting; DroPE enables longer context for that fine-tuning. You could fine-tune on long-document medical records (DroPE enables the length) without destroying general capabilities (EAFT prevents forgetting).
Trade-offs and Constraints
Trade-offs and Constraints
EAFT is the easiest to adopt—it's a simple loss modification with minimal overhead. Already integrated into LLaMA-Factory.
DroPE requires a one-time recalibration cost, but after that, inference is unchanged. Good for organizations with existing models they want to extend.
TTT-E2E has the highest implementation barrier (architecture changes, custom training) but offers the best scaling for very long context. Best for labs willing to train from scratch.
RLMs require orchestration infrastructure but work with existing models out-of-the-box. Good for immediate deployment on extreme-context tasks.
Philosophical Differences
Philosophical DifferencesWhere learning happens:
EAFT: Training time (modified loss function)TTT-E2E: Test time (meta-learned initialization enables on-the-fly training)DroPE: Training time (architectural modification with test-time benefits)RLMs: Inference time (pure inference strategy)
Memory philosophy:
EAFT: Selective gradient updates preserve memoryTTT-E2E: Compress context into weights like human memoryDroPE: Remove architectural constraints on memoryRLMs: Offload memory to external environment
Distribution alignment:
EAFT: Explicitly analyzes SFT vs RL distributional gapsTTT-E2E: Aligns with human memory modelDroPE: Recognizes training vs inference distribution mismatchRLMs: Treats context as environment (out-of-core algorithm inspiration)
A Hypothetical Combined System
A Hypothetical Combined SystemImagine training a model with this pipeline:
Pre-training: Use RoPE for stability and fast convergence (standard practice)Post-training: Apply DroPE—remove PEs with 0.5% recalibration budget. Model now generalizes to arbitrary context lengths.Domain adaptation: Use EAFT to fine-tune for specific domains (medical, legal, code) without forgetting general capabilitiesTest time compression: TTT-E2E compresses relevant context into weights. For a legal analysis task, compress the relevant case law.Ultra-long context: When inputs exceed even TTT-E2E's capacity, RLMs handle decomposition. For an entire legal database, RLMs identify relevant cases, then TTT-E2E processes them.
This system would:
Generalize to arbitrary context lengths (DroPE)Learn new domains without forgetting (EAFT)Efficiently process long context at test time (TTT-E2E)Handle arbitrarily long inputs via decomposition (RLMs)
Can They All Be Combined? A Stress Test
Can They All Be Combined? A Stress TestLet's seriously examine a "kitchen sink" approach: use all four methods together.
Here's a naive way one could conceive of combining them all.
Proposed Pipeline:
Pre-train with RoPE (standard)Apply DroPE recalibration (0.5% compute)Fine-tune with EAFT loss (for domain adaptation)Deploy with TTT-E2E test-time compressionWrap with RLMs for extreme-context tasks
Where This Breaks Down:
Where This Breaks Down:Step 2→3 interaction: DroPE removes positional embeddings. EAFT was developed and tested on models with positional embeddings. Does EAFT's entropy-based gating work the same way on DroPE models? The attention patterns are different after DroPE—confident conflicts might manifest differently. Untested.
Step 3→4 interaction: EAFT fine-tuning produces a model with certain weight configurations. TTT-E2E expects a specific meta-learned initialization. If you EAFT-fine-tune a TTT-E2E model, do you destroy the meta-learned properties that make test-time training work? Untested.
Step 4→5 interaction: TTT-E2E compresses context into weights. RLMs assume the model has fixed weights and manage context externally. If TTT-E2E is updating weights at test time, and RLMs are making recursive calls, each call might have different weights. Is this desirable? Problematic? Completely unexplored.
DroPE + TTT-E2E compatibility: TTT-E2E uses attention within chunks, presumably with RoPE. DroPE removes RoPE entirely. Can TTT-E2E work without intra-chunk positional information? The chunked architecture might actually require positional embeddings to distinguish token order within chunks. Potentially incompatible.
The Honest Assessment:
The Honest Assessment:These methods were developed independently by different research groups solving different problems. Their interactions are largely unexplored. The "combine everything" approach is intellectually appealing but practically untested.
What we can say with confidence:
What we can say with confidence:EAFT + DroPE: Likely compatible (both are training-time modifications that don't interact)DroPE + RLMs: Likely compatible (DroPE changes the base model; RLMs wrap any model)EAFT + RLMs: Likely compatible (same reasoning)TTT-E2E + anything: Uncertain (architectural changes may not compose)
What needs research:
What needs research:TTT-E2E + DroPE: Do positional embeddings matter for chunked attention?EAFT + TTT-E2E: Does entropy gating help or hurt test-time training?Full pipeline integration: Does the combination preserve each method's benefits?
Open Questions
Open QuestionsSeveral questions remain for the research community:
Can these methods be trained jointly? Current papers present independent contributions. What happens when you combine EAFT training with TTT-E2E meta-learning?
How do these interact with reasoning models? o1-style test-time compute scaling is orthogonal to these approaches. Could extended thinking benefit from TTT-E2E compression or RLM decomposition?
What's the information-theoretic limit? How much context compression is possible before information loss becomes unacceptable? TTT-E2E suggests substantial compression is possible, but where's the boundary?
Can RLMs be trained? Current RLMs use frozen LLMs with no RLM-specific training. The authors suggest that RLM trajectories could be treated as a form of reasoning to be learned. What gains are possible with specialized training?
What This Means for You
What This Means for YouIf you're a practitioner, here's the practical takeaway from each paper:
EAFT: If you're fine-tuning models and losing capabilities, try EAFT. It's already in LLaMA-Factory (use_eaft_loss parameter). The gains are significant with minimal implementation overhead.
TTT-E2E: For long-context applications where you need both speed and quality, watch this space. The current implementation has limitations (3.4x slower meta-learning), but the approach shows genuine promise. When better kernels arrive, this could change how we think about context.
DroPE: If you have a pretrained model and need better length generalization, DroPE offers a remarkably cheap solution. 0.5-5% of pretraining compute for dramatically better long-context performance is an excellent trade-off.
RLMs: For tasks requiring 1M+ token inputs, RLMs provide a framework that actually works today. The code is available, and the performance gains over base models are dramatic—especially for information-dense tasks.
The Road Ahead
The Road AheadThe dream of continual learning—AI that learns and adapts without forgetting—is getting closer. These four papers show that progress is coming from multiple directions:
Smarter training that respects what models already know (EAFT)Test-time adaptation that compresses context into intuitive knowledge (TTT-E2E)Architectural flexibility that removes training-time constraints (DroPE)Inference strategies that let models manage their own context (RLMs)
None of these approaches alone solves the full problem. But together, they suggest a path forward where models can:
Learn new things without destroying old knowledgeProcess arbitrarily long context efficientlyGeneralize beyond their training distributionManage their own memory and attention
2026 might be the year these pieces start coming together. The foundations are being laid.
For deeper technical details, check out the original papers and code repositories linked throughout this article. The researchers have released implementations for all four approaches.
Also, we're not ML researchers here at The Neuron, merely ML hobbyists, so if you catch any errors or misconceptions, let us know at grant@theneurondaily.com and we'll update and credit you. :)
