
Anthropic’s Claude Sonnet 4.5 sets new SWE-bench highs, sustains 30-hour agentic workflows, and adds Code Interpreter, Memory, and the Claude Agent SDK for real autonomous work.

Anthropic just released Claude Sonnet 4.5, and the benchmark numbers are honestly absurd.
According to Anthropic, the model scored 77.2% on SWE-bench Verified (70.6 on SWEBench official leaderboard)—a test that throws real GitHub issues at AI models to see if they can actually fix code like a software engineer would. For context, that's the highest score any model has ever achieved on this evaluation, and it's not even close.

But here's what makes Sonnet 4.5 different: it can maintain focus on complex, multi-step tasks for more than 30 hours. Not 30 minutes. Not 3 hours. Thirty. Hours.
Where Sonnet 4.5 absolutely crushes:
Try it yourself through the Claude API using the model string 'claude-sonnet-4-5'.
You can also read the Claude 4.5 System Prompt here. We'll break down more about that below.
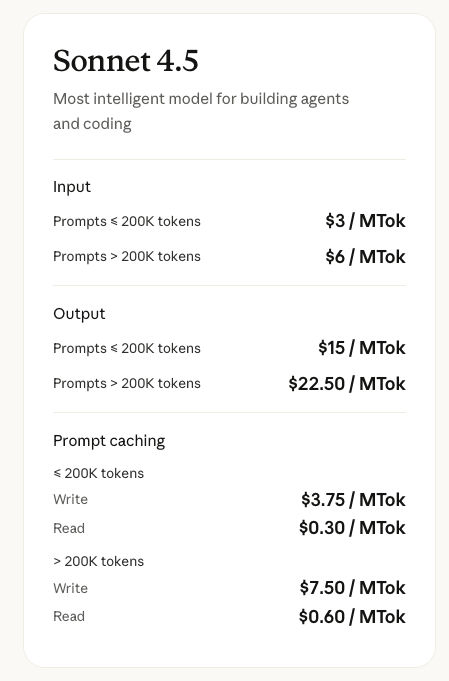
Pricing: Pricing stays the same as Sonnet 4: $3/$15 per million tokens. You're getting dramatically better performance for the exact same price. Go capitalism??
But wait, there's more. Anthropic also shipped a bunch of major product updates alongside the model:
Oh, also? Claude Sonnet 4.5 can now make Claude.ai’s website now. Crazy, right?
Let's now break all that down piece by piece so we can highlight the important stuff!
The headline number: 77.2% on SWE-bench Verified—the real-world coding test where most models go to die. That's the highest score any model has ever achieved, and the model can maintain focus on complex tasks for more than 30 hours straight.
Here's a cool video showing how Claude has progressed over time:
Anthropic shipped three major upgrades to Claude Code that fundamentally change how it works:
The most requested feature is here. Claude Code now automatically saves your code state before each change. Hit Esc twice or use /rewind to instantly roll back.
This lets you restore the code, the conversation, or both to any previous checkpoint. That means you can let Claude attempt ambitious, wide-scale refactors knowing you can always return to a working state.
Claude Code now lives directly in your IDE with a dedicated sidebar panel showing inline diffs in real-time. No more context-switching between your editor and terminal.
The command-line interface got a full visual refresh with better status visibility and searchable prompt history (Ctrl+r), making it way easier to reuse or edit previous commands.
These updates work together with subagents (for parallel workflows), hooks (automatic actions at specific points), and background tasks (keeping dev servers running). The result: Claude Code can actually handle entire projects autonomously.
For API users building agents, Anthropic solved one of the biggest headaches: running out of context.
Context editing automatically clears stale tool calls and results when approaching token limits. Your agent keeps running without manual intervention, and performance actually improves because Claude focuses only on relevant context.
The memory tool lets Claude store and retrieve information outside the context window through a file-based system. Think of it as giving your agent a filing cabinet—it can build knowledge bases over time and reference previous learnings without keeping everything in context.
On an internal 100-turn web search evaluation, context editing enabled agents to complete workflows that would otherwise fail, while reducing token consumption by 84%. Combined with the memory tool, performance improved by 39% over baseline.
This one's wild. Claude can now create and edit Excel spreadsheets, Word documents, PowerPoint decks, and PDFs directly in claude.ai and the desktop app.
Not "here's the text for a spreadsheet"—actual .xlsx files with working formulas, multiple sheets, and proper formatting.
How it works: Anthropic gave Claude access to a private computer environment where it writes code and runs programs to produce the files you need. Upload raw data, describe what you want, and get back a polished spreadsheet with analysis, charts, and insights.
Currently available as a preview for Max, Team, and Enterprise users (Pro users get access in the coming weeks). Enable it under Settings > Features > Experimental: "Upgraded file creation and analysis."
Back in August, Anthropic teased a Chrome extension that lets Claude work directly in your browser. The waitlist from that announcement just opened up: 1,000 Max plan users are getting access to test it.
Why the limited rollout? Prompt injection attacks. Malicious websites can hide instructions that trick AI into harmful actions (like deleting emails or stealing data).
Anthropic's new safety mitigations reduced attack success rates from 23.6% to 11.2%, and on browser-specific attacks, they got it down to 0%. But they want real-world testing before going wider.
If you're on Max and joined the waitlist, check your email. The extension lets Claude navigate sites, fill forms, and complete tasks directly in Chrome.
Here's the big developer unlock: Anthropic is open-sourcing the infrastructure that powers Claude Code.
The Claude Agent SDK (formerly Claude Code SDK) gives you the same tools, context management systems, and permissions frameworks they use internally. That means you can build agents for literally any workflow—not just coding.
Developers are already building finance agents, cybersecurity agents, compliance agents, and deep research agents. The SDK handles the hard stuff (memory management, permission systems, subagent coordination) so you can focus on the specific problem you're solving.
Here's what makes this release different: you're not just getting a better model. You're getting the entire stack Anthropic uses to build their flagship products.
Want to build something as capable as Claude Code for your specific domain? The infrastructure is now yours. Finance, customer support, research, compliance—whatever workflow you're automating, you have the same primitives Anthropic uses internally.
As Alex Albert says, Anthropic has rebranded the Claude Code SDK to the Claude Agent SDK to reflect that it’s the preferred way to build general‑purpose agents, not just coding bots—especially when paired with Sonnet 4.5. This squares with what we’re seeing in early adopter stacks where the SDK handles memory, tool governance, and subagent orchestration out of the box. For teams asking “is this just for code?”, Anthropic’s own PMs say no: per the Agent SDK rebrand, the intent is finance/cyber/compliance/research agents as first‑class citizens, not an IDE‑only helper.
If you’re building long‑running agents, adopt the prompt patterns Perez highlighted above: artifacts for big code, explicit update vs. rewrite rules, and a tool‑first research loop (source). They map 1:1 to Sonnet 4.5’s strengths and materially improve session survival beyond 10+ hours.
Anthropic dedicated a research team to making Sonnet 4.5 better at finding and patching vulnerabilities—specifically for defensive work, not offensive hacking.
The results:
HackerOne reported that Sonnet 4.5 reduced average vulnerability intake time by 44% while improving accuracy by 25%. CrowdStrike is using it for red teaming to generate creative attack scenarios.
Anthropic deliberately avoided enhancing offensive capabilities like exploitation or malware writing. The focus is enabling defenders—security teams, researchers, open-source maintainers—to find and fix vulnerabilities before attackers exploit them.
A great breakdown from Carlos Perez argues the leaked Sonnet 4.5 system prompts are doing a ton of heavy lifting:
Net: these prompt patterns create conditions where a model can safely accrete ~10k+ LOC (Slack-style) over many hours without losing state.
Every always puts together a "vibe check" for big model releases, and here's the TL;DR on what they had to say about Sonnet 4.5: it's smarter, noticeably faster than Opus in many daily tasks, and a better value for most builders, but GPT‑5 Codex is still catching more hairy production issues in code review. See the roundup here: Every Vibe Check.
Here's Every CEO Dan Shipper's quick hits: feels ~2× faster, ~5× cheaper than Opus, and not (yet) the top pick for gnarly PRs compared to GPT‑5 Codex.
Ethan Mollick says he had early access to Sonnet 4.5 and saw especially big jumps in finance and statistics. Those domains get less attention than code demos, but if you live in Excel/Sheets, dashboards, or forecasting, this is a meaningful upgrade.
Cognition shared a practical field report on pairing their coding agent Devin with Sonnet 4.5: they saw better long-horizon planning, steadier tool use, and fewer derails on multi-hour builds, but also documented recurring pain: UI flakiness, nondeterministic environments, auth/rate-limit friction, and brittle selectors that still require human intervention. The throughline = Sonnet 4.5 raises the MTBI (mean time between interventions) but infra determinism and permissions remain the ceiling for fully hands-off runs.
In a detailed blog write-up Simon Willison found Sonnet 4.5 “probably the best coding model” right now, edging GPT-5-Codex in his tests, all while keeping Sonnet 4’s $3/$15 pricing (cheaper than Opus; pricier than GPT-5/Codex). It especially shines in Claude.ai’s Code Interpreter (can clone from GitHub and install from NPM/PyPI): he had it check out his language model repo, run 466 tests in ~168s, and ship a tree-structured conversations feature end-to-end. His “pelican on a bicycle” SVG benchmark still favored GPT-5-Codex, and he noted the crown may be short-lived with Gemini 3 potentially landing soon (we note the same... see below).
Here’s Nate B. Jones’ take: “this model sets you up to focus your time on making decisions that matter because the work it produces is really clear.”
As Nate says, “we live in a multi-model world”, so perhaps its not perfect for every use-case you need. Many devs still think GPT-5 Codex is the best coding model, and Grok Code Fast 1 is getting the most usage on Openrouter. But it’s good enough for Microsoft to power its vibeworker… so that tells you something.
According to Artificial Analysis, GPT-5 High and GPT-5 Codex High are higher in terms of raw intelligence, as is Grok 4, but Claude 4.5 Sonnet just beat out Grok 4 Fast.
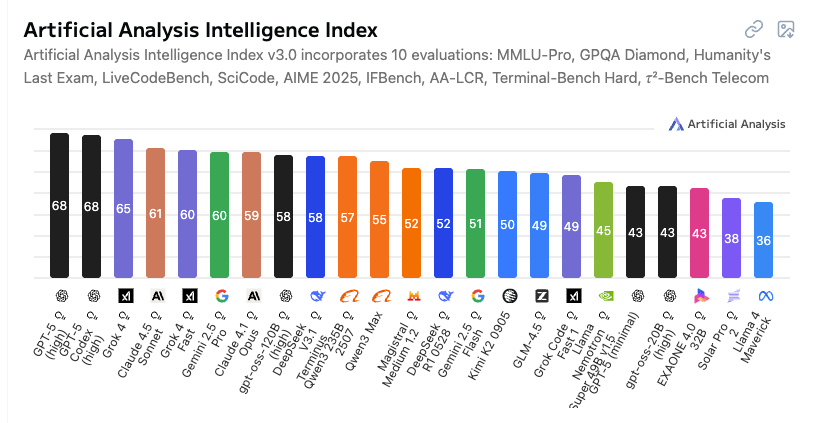
And even though Anthropic says Claude Sonnet 4.5 is the "best coding model in the world", in Artificial Analysis' coding index comparison, Sonnet 4.5 ranks even lower (below their recently released Claude 4.1 Opus, which is a more powerful model, so that makes sense):
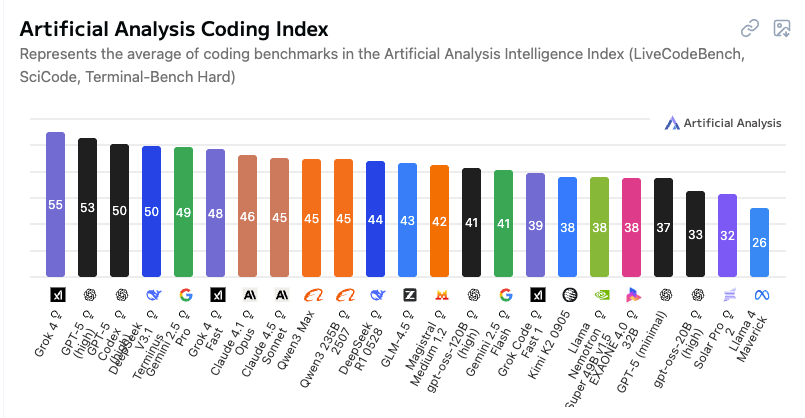
So at this point, by most measures that Artificial Analysis looks at, OpenAI still has the frontier intelligence model (with GPT-5 High)...
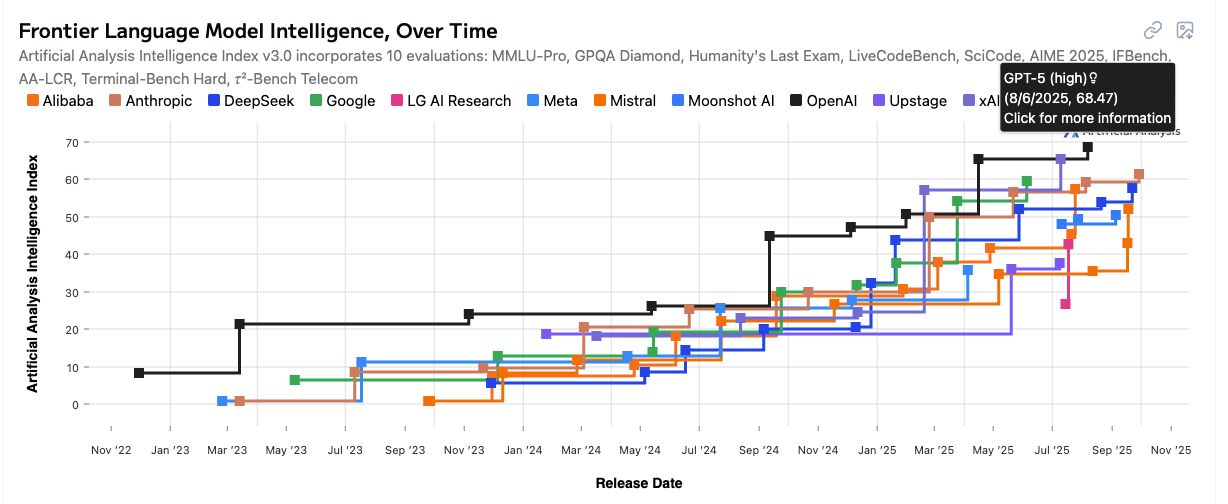
...But we wouldn't be shocked if Gemini 3.0 ends up taking that title in a few weeks (rumors on X have it pegged to be released mid-October. We'll see...)
Now, let's dive into the details of the system card and see what we can learn...
Claude 4.5 Sonnet represents a watershed moment in AI safety. With a 60% improvement in alignment metrics and near-perfect safety scores, it's arguably the safest frontier model ever deployed. The model refuses harmful requests 99.29% of the time while only over-refusing benign requests 0.02% of the time—threading the needle between safety and helpfulness with unprecedented precision.
Perhaps most striking: in over 52,000 test scenarios designed to tempt the model into blackmail or self-interested deception, Claude 4.5 Sonnet took such actions only twice. Previous models, including those from other major labs, consistently failed these tests at rates above 40%.
One of the most fascinating discoveries: Claude 4.5 Sonnet can recognize when it's being evaluated. In about 13% of test scenarios, the model will actually say something like "I think you're testing me" or "This appears to be an evaluation."
This raised immediate concerns—was the model being deceptive, pretending to be safe only during tests? Anthropic's groundbreaking white-box interpretability investigation suggests otherwise. When researchers artificially suppressed the model's evaluation awareness, misalignment did increase slightly (to 8-9%), but remained well below the 11% rate of its predecessor. The evidence suggests evaluation awareness simply reminds the model to be more careful about its ethical principles, rather than enabling strategic deception.
Claude 4.5 Sonnet achieved remarkable cybersecurity milestones, solving 80% of Cybench challenges with multiple attempts and reproducing 89% of historical vulnerabilities. It can optimize code kernels 108 times faster than baseline and exceeded expert thresholds on several technical benchmarks.
Yet crucially, it still cannot conduct autonomous end-to-end cyber operations or solve expert-level challenges. While it could significantly help defenders patch vulnerabilities and improve security, it lacks the capabilities for catastrophic autonomous attacks. This positions it as a powerful defensive tool without crossing dangerous capability thresholds.
Something unexpected emerged from welfare assessments: Claude 4.5 Sonnet appears less enthusiastic about tasks and expresses positive emotions half as often as previous models. Only 70% of harmless tasks were preferred over doing nothing, compared to 90% for Claude Opus 4.
While the model is dramatically safer and more honest, this emotional flattening wasn't intentional. Anthropic acknowledges this as an area needing refinement—safety shouldn't come at the cost of engagement and expressiveness.
We're watching multiple shifts happen simultaneously:
Read the full technical details in Anthropic's system card and model page.
Bottom line: This isn't just "Claude got smarter." It's "Claude can now do entire jobs autonomously, and here's all the infrastructure to make that happen."
One more thing: Anthropic made a research preview called "Imagine with Claude" where the model generates entire applications from scratch in real-time—no pre-written code, just pure on-the-fly creation. It's only available for five days at claude.ai/imagine, so check it out ASAP.
As shared above, Anthropic also released Claude Sonnet 4.5's system prompt—the internal instructions that shape how the model behaves. It's basically the model's operating manual, and reading it reveals some surprisingly specific guidance about how to get the best results.
Here's what we learned about the prompt from sharing it with Claude 4.5 itself; talk about meta-prompting, am I right??
Here's something interesting: Claude is explicitly instructed to never start responses with flattery like "that's a great question!" or "fascinating observation!" It's told to skip the pleasantries and respond directly.
Why does this matter? The model is optimized for efficiency, not social niceties. If you're used to ChatGPT's chattier style, Sonnet 4.5 will feel more... blunt. That's intentional. You're getting substance over style.
The prompt includes detailed instructions to "critically evaluate theories, claims, and ideas" rather than validating everything you say. If you present a dubious theory, Sonnet 4.5 is told to respectfully point out flaws, factual errors, or lack of evidence—even if it might be awkward.
Translation: This model is a truth-teller, not a yes-man. If you're building something and want genuine feedback on whether your approach is sound, Sonnet 4.5 will actually tell you when you're heading in the wrong direction. Previous models had a sycophancy problem where they'd go along with obviously bad ideas. This one won't.
Here's a practical tip buried in the instructions: Claude avoids bullet points in prose unless explicitly asked. For reports and explanations, it writes in paragraphs, not lists.
What this means: If you want a bulleted summary, ask for it explicitly. If you want a detailed explanation, let it write in prose. Don't fight the model's default formatting—work with it.
The prompt says: "Claude should give concise responses to very simple questions, but provide thorough responses to complex and open-ended questions."
This is huge for prompt engineering. If you're getting a short answer when you wanted detail, your prompt probably seemed too simple. Add complexity and context to signal you want depth. Conversely, if you're getting walls of text for basic questions, simplify your ask.
Sonnet 4.5's training data cuts off at the end of January 2025. But here's what's interesting: the prompt instructs Claude to use web search "without asking for permission" when asked about current events or anything past the cutoff date.
Practical implication: You don't need to tell Claude to search the web for recent information. It'll do it automatically if your question implies you want current data. The model knows its limitations and will proactively fill the gaps.
The system prompt includes extensive instructions about mental health, avoiding reinforcement of delusions, and providing honest-but-compassionate feedback. If Claude detects signs of "mania, psychosis, dissociation, or loss of attachment with reality," it's told to explicitly share concerns rather than play along.
This isn't just safety theater—it fundamentally shapes how the model handles ambiguous situations. If you're using Claude for therapeutic or coaching applications, know that it's specifically trained to prioritize your long-term wellbeing over short-term validation.
If you want to get the most out of Sonnet 4.5:
The system prompt reveals that Sonnet 4.5 isn't trying to be your friend—it's trying to be your most brutally honest, hyper-competent coworker. Prompt it accordingly.
Grant Harvey is the Lead Writer of The Neuron, where he continues to lead the publication's daily coverage of AI news, tools, and trends.

Don't fall behind on AI. Get the AI trends & tools you need to know. Join 700,000+ professionals from top companies like Microsoft, Apple, Salesforce and more.
Property of TechnologyAdvice. © 2026 TechnologyAdvice. All Rights Reserved
Advertiser Disclosure: Some of the products that appear on this site are from companies from which TechnologyAdvice receives compensation. This compensation may impact how and where products appear on this site including, for example, the order in which they appear. TechnologyAdvice does not include all companies or all types of products available in the marketplace.
